Notebook|CNetNotebook||计算机网络自顶向下方法笔记
计算机网络
计算机网络基础
按照《计算机网络自顶向下》的目录整理的相关笔记
1. 计算机网络
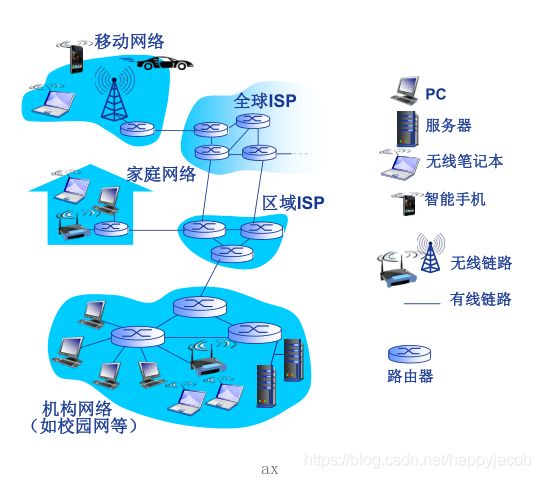
构成因特网的软件和硬件,根据分布式应用提供服务的联网基础设施来描述因特网
世界范围内的计算机网络 因特网就是将端系统彼此互联
1.1 具体构成和描述
端系统,分组Packet
- 所有连接的设备,叫做主机或者端系统 HOST END SYSTEM
- 端系统通过通信链路communication link和分组交换机连接在一起
- 通信链路又不同类型的物理媒介组成,链路的传输速率为 BIT/S bps 比特每秒来计算
- 分组Packet,发送端将数据分段并为每段加上首部字母,这样的信息包叫做分组
分组交换机
- 分组交换机,从交换机的一条入链路将分组转发并从出通信链路发出
- 分组交换机包括,路由器Router,链路层交换机Link-layer switch
- 链路层交换机用于接入网,路由器用于核心网
通信链路
- 从发送端到接收端系统,一个分组所经历的一系列的通信链路和分组交换机称为通过该网络的路径,Path Route
- 分组类似于运载货物的卡车,通信链路类似于公路,分组交换机类似于立交桥;
- 链路的速率,主要取决于分组交换机的转发能力: RM bps表示路由器在1S内可以完成R兆bit的转发
ISP
- 端系统由 ISP internet service provider 接入因特网
- 每个ISP是一个由多个分组交换机和多段通信链路组成的网络,各ISP为端系统提供了各种不同类型的网络接入
- 底层ISP通过国际的高层ISP互联,独立管理,运行着IP协议
- 调制解调?
协议 Protocol
协议控制着网络中或因特网中的信息接受和发送,TCP和IP协议是最重要的两个协议,主协议统称为TCP/IP
TCP Transmission Control Protocol 控制传输协议
IP Internet Protocol 网际协议,IP协议定义了在路由器和端系统之间发送和接受的分组格式
背景,Internet Standard 由 InternetEngineering Task Force研发,其他组织也会制定标准,例如以太网标准,Wi-Fi标准
服务描述
- 应用程序提供服务的基础设施:分布式应用程序 distributed application,application运行在端系统上,分组交换机并不关心作为数据源或者宿的应用程序
- 端系统提供应用程序编程接口,API,API规定了运行在一个端系统上的软件向另一个端系统的特定目的地软件交付数据的方式
协议
- 因特网中涉及两个或者多个远程通信的实体活动都受到协议的制约,交换报文或者采取动作的实体是硬件或者软件
- 硬件实现的协议控制了在两块“接口卡”之间的“线上”比特流
- 端系统中,拥塞控制协议控制了发送方和接受方之间传输的分组Packet发送频率
- 一个协议定义了两个或者多个通信实体之间的交换的报文格式和次序,以及报文发送和接受所采取的动作(一系列约定俗成的动作);
- 构成,原理,工作方式;
1.2 网络边缘 - 边缘计算
- 在因特网中处于边缘的系统,叫做端系统;
- 主机 = 端系统 HOST = END SYSTEM ,主机被划分为两类:Clinet和Server。web服务器属于大型的数据中心Data Center,client通常为桌面级pc和手机等,server为更为强大的服务器
接入网
端系统和应用程序位于网络边缘,access network,接入网是将端系统接到其边缘路由器的物理链路(edge router)- 端系统接入边缘路由的链路
边缘路由器,是端系统到其他任何远程端系统路径上的第一台路由器
端系统 —(A)— 边缘路由(第一台路由) A:这样的一条链路称为接入网
上下行速率由编码频率控制,频率越高,速度越高,家庭DSL,家庭接入同轴电缆
调制解调为外部设备
物理链路的搭建方式
家庭接入
- 数字用户线和电缆
以太网和wifi
- 局域网将端系统连接到边缘路由,以太网为接入技术
广域无线接入
- 5G
物理媒介
- 通过跨越物理媒介 Physical Medium传播电磁波活着光脉冲来发送bit;
- 物理媒介:引导型媒介,电磁波沿着物理媒介前进;非引导型媒介,电磁波沿着空气前进
- 双绞铜线、同轴电缆、光纤等
1.3 网络核心
- 网络核心:由互联因特网端系统的分组交换机和链路构成的网状网络;
- 分组交换机包括路由和链路层交换机;
分组交换
端系统彼此交换报文(message),报文包含了协议设计者需要的所有的东西;
源端系统向目的端系统发送一个报文,“源”将长报文划分为较小的数组快,为“分组”Packet;
在源和目的之间,每个分组都通过通信链路的分组交换机(packet swith)传送;路由器和链路层交换机
每个分组以等于该链路最大传输速率的速度传输通过通信链路
一个Lbit的分组,链路速率为Rbit/s,则传输时间为L/R s
存储转发传输
- 指交换机在开始向输出链路传输该分组的第一个bit前,必须已经接收到了整个分组;缓存分组比特,当路由器由输入链路接收完了整个分组后(此时花费L/R的时间),才开始向出链路传输(传输完成需要花费L/R),总延时为2L/R s
- N条速录为R的链路,转发一个分组,d源到端 = N L/R
排队时延和分组丢失
- 每个分组交换机与多条线路相连,分组交换机有一个输出缓存,output buffer,output Queue;到达的分组的传输链路处于繁忙状态,传输其他分组,达分组会在“输出缓存”中等待;
- 时延,1. 存储转发时延,2. 排队时延,时延处于变化的状态,变化程度取决于网络中的拥塞程度
- 丢包,一个分组发现“输出缓存”已经被其他的等到传输的分组完成充满了,这时就会出现“分组丢包”,Packet lost,到达分组或者已经排队的分组之一会被丢弃;
- 分组达到率(每秒比特)超过了输出链路的速率,这些分组在通过链路传输前,在“链路输出缓存中排队”,在该路由器中将出现拥塞;
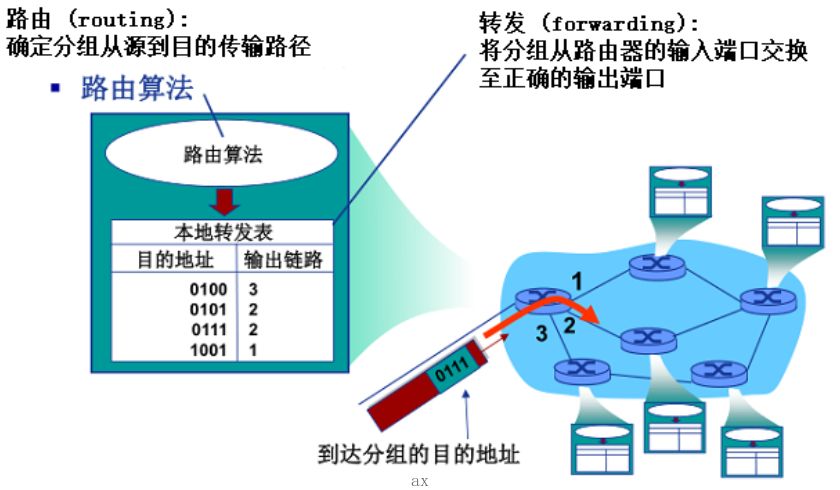
转发表和路由选择协议
- 因特网中,每个端系统具有IP地址,源向目的端发送分组,分组的首部都包含了IP地址;
- 路由器具有转发表,forwarding table,用于将目的地址(或者地址中的几段)映射为输出链路;
- 分组到达路由器,路由器检查分组地址,并用目的地址搜索转发表,发现出链路,则将该分组导向出链路;
- 转发表配置问题,路由选择协议 routing protocol,用于自动设置转发表;
电路交换
- 网络链路和交换机转发数据的两种基本方式:1. 电路交换 2. 分组交换;
- 电路交换需要提前预留报文要使用的资源,缓存链路传输速率等,传统的电话就是一种电路交换,连接期间预留了恒定的传输速率;
- 实现方式:频分复用 Frequency-Division Multiplexing, 时分复用Time-Division Multiplexing;
- 带宽 bandwidth:频段的宽度 80——100Mhz;
- 相关计算在P21
分组交换和电路交换的对比
分组交换的性能优于电路交换;
例子:假设10个用户,某个用户产生1000个1000bit的分组,其他用户保持静默。每帧具有10个间隙且每个间隙保护1000bit的TDM电路交换情况下,活跃用户只能使用每帧中的一个间隙来传输数据,传完1000,000的bit数据需要10S时间,而分组交换的情况下,活跃用户能连续的以1Mbps的速率使用链路,完成数据的发送只需要1S;
电路交换需要预先分配传输链路,使得已分配但是不需要的链路时间未被使用;分组交换按需分配链路使用,链路传世能力在所有用户之间逐分组共享;
优点 缺点 分组交换 ① 加速了数据在网络中的传输。因为分组是逐个传输,可以使后一个分组的存储操作与前一个分组的转发操作并行,这种流水线式传输方式减少了报文的传输时间。此外,传输一个分组所需的缓冲区比传输一份报文所需的缓冲区小得多,这样因缓冲区不足而等待发送的机率及等待的时间也必然少得多。② 简化了存储管理。因为分组的长度固定,相应的缓冲区的大小也固定,在交换结点中存储器的管理通常被简化为对缓冲区的管理,相对比较容易。③ 减少了出错机率和重发数据量。因为分组较短,其出错机率必然减少,每次重发的数据量也就大大减少,这样不仅提高了可靠性,也减少了传输时延。④ 由于分组短小,更适用于采用优先级策略。 ① 尽管分组交换比报文交换的传输时延少,但仍存在存储转发时延,而且其结点交换机必须具有更强的处理能力。② 分组交换中的每个分组都要加上源、目的地址和分组编号等信息,这将增大传送的信息量,一定程度上降低了通信效率,增加了处理的时间,使控制复杂,时延增加。③ 当分组交换采用数据报服务时,可能出现失序、丢失或重复分组,分组到达目的结点时,要对分组按编号进行排序等工作,增加了麻烦。若采用虚电路服务,虽无失序问题,但有呼叫建立、数据传输和虚电路释放三个过程。 电路交换 ① 由于通信线路为通信双方用户专用,数据直达,所以传输数据的时延非常小。② 通信双方之间的物理通路一旦建立,双方可以随时通信,实时性强。③ 双方通信时按发送顺序传送数据,不存在失序问题。④ 电路交换既适用于传输模拟信号,也适用于传输数字信号。⑤ 电路交换设备控制均较简单。 ① 电路交换的平均连接建立时间对计算机通信来说偏长。② 电路交换连接建立后,物理通路被通信双方独占,即使通信线路空闲,也不能供其他用户使用,因而信道利用低。③ 电路交换时,数据直达,不同类型、不同规格、不同速率的终端很难相互进行通信,也难以在通信过程中进行差错控制。
网络的网络
- 十多个第一层ISP和数十万个底层ISP组成,ISP覆盖大洲,大洋,有些覆盖小的地理区域;底层与高层互联,高层彼此互联;
1.4 分组交换网中的时延、丢包、吞吐量
时延:节点处理时延,排队时延,传输时延,传播时延,节点总时延;
处理时延,检查分组首部需要的处理时延,用来决定将该分组导向何处
排队时延,分组在链路上等待传输是排队的时延(“输出缓存” output buffer)
传输时延/发送时延,数据长度/信道带宽 先到先服务,仅当所有已到达分组被传输后,才能传输刚到达的分组,链路速率R bps,R个bit每秒,时延=分组比特/链路速率,毫秒微秒量级
传播时延,信道长度/传播速率,是分组从一个路由器传输到另一个路由器,所在的链路的传播需要的时间,它和链路的物理长度及物理媒介有关,和链路的速率以及分组长度无关;
区别:传输时延是由路由器将整个分组推出所需要的时间,这里的速率完全取决于路由器的转发能力,R Mbps表示路由器在1S内可以完成R兆bit的转发,速率也和编码频率有关; 传播时延表示分组或者数据比特在物理或者媒介中传播所需要的时间;

排队时延和丢包
- 排队时延取决于流量到达该队列的速率,链路传输的速率和流量到达的性质;
- R表示链路的传输速率,就是从队列中推出bit的速率 bps
- 假设a表示分组达到队列的速率,L表示分组的比特数量,则La bps表示比特到达队列的平均速率,La/R为 流量强度 traffic intensity; 流量强度不能大于 1
丢包
- 随着”流量强度” 接近1,分组交换机或路由器将会对已经满了的队列,丢弃新的分组,Drop,该分组将会丢失Lost;
- 一个结点的性能是根据分组的丢失概率来度量的;
端到端时延
- N-1台路由器 总时延 = N (主机和路由器上的处理时延 + 链路传播时延 + 传输时延L/R
- traceroute软件做时延分析
端系统、应用程序、其他时延
- 对于某些协议,端系统application处理的延时;
吞吐量
- 单位时间通过某个接口的数据量
- 瞬时吞吐量:端系统接受到该文件的速率 bps,例如下载文件的的速率显示
- 平均吞吐量:F比特的文件,主机接收到所以的bit用了T秒时间,平均吞吐量为F/T
- 有些Application中吞吐量比时延更重要;
- Rs表示服务器与路由器之间的链路速率,Rc表示路由器和客户端之间的链路速率,对于Server来说他的吞入量为min{Rs, Rc},这里的吞入量为瓶颈链路速率,bottleneck link,当然这里的吞吐量还需要考虑分组层次和传输协议的问题;
- 吞吐量取决于数据流过链路的传输速率;在没有其他条件干扰时,吞吐量近似等于源和目的之间的最小传输速率;
bandwidth 带宽
网络设备所能支持的最高速度,理想的极限传输速率
Bandwidth (signal processing) or analog bandwidth, frequency bandwidth or radio bandwidth, a measure of the width of a range of frequencies, measured in hertz
Bandwidth (computing), the rate of data transfer, bit rate or throughput, measured in bits per second (bit/s)
Spectral linewidth, the width of an atomic or molecular spectral line, measured in hertz
对于信号处理中,bandwidth表示当前信号的频段宽度,例如模拟信号或者数字信号的”频率范围“ hz为单位
对于计算机网路链路,带宽为当前最大传输速率,没秒钟链路能够传输或处理的比特,bit/s为单位,注意在电路交换中带宽表示的是频率范围;
时延带宽积
- *时延带宽积(bit)=传播时延(s)带宽(bit/s)
- 时延带宽积是描述一个链路中,此时此刻的bit数量
往返时延RTT
- 从发送方发送数据开始,到发送方收到接收方的确认(接收方收到后立即发送确认),总共经历的时延
- RTT包括:*2传播时延、末端处理时间**
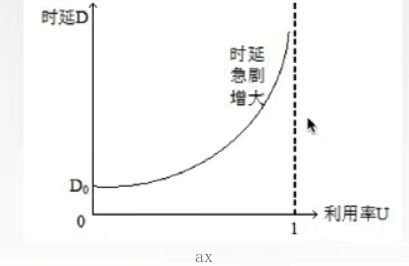
利用率
- 信道利用率=有数据通过时间/总共时间
- 网络利用率=信道利用率加权平均值
1.5 协议层次及其服务模型
协议分层
- 网络以分层的方式组织协议,某层会向上一层提供服务,就是服务模型;
- 应用层协议在端系统中以软件方式实现,物理层和数据链路层则复杂处理跨越链路的通信,通常实现在给定的接口卡中;网络层则有软硬件的混合;
协议栈
- 各层所有的协议被称为协议栈 protocol stack
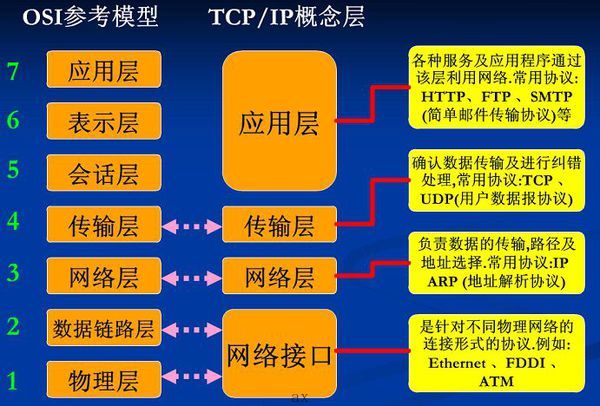
- 因特网的协议栈由5层组成 1. 物理层 2. 数据链路层 3. 网络层 4. 传输层 5. 应用层
- 应用层:用户与网络的界面,网络应用程序之间定义的协议留存的分层,分布在多个端系统上,一个端系统的应用程序使用协议与另一个端系统中的应用程序交换信息的分组,位于应用层的信息分组称为报文(message)FTP、SMTP、HTTP
- 表示层:数据格式的变换、数据的解密加密、数据的压缩和恢复
- 会话层:像表示层提供建立连接并且有序的传输数据
- 传输层、运输层:用于传输应用层报文,主要有TCP和UDP,TCP向他的应用程序提供了面向连接的服务。TCP也将长报文划分为短报文,提供拥塞机制;TCP源代码;UDP无连接,不提供服务的服务,运输分组可以称为报文段 segment,端到端的通信。可靠传输、差错控制、流量控制、复用分用功能 主要协议: TCP、UDP
- 网络层:分组单位是数据报 datagram,将数据报 datagram 的网络层分组从一台主机移动到另一台主机;源主机中TCP或者UDP运输协议向网络层递交运输层报文段segment和目的地址,网络层IP协议定义了数据报中的各个字段和端系统及路由器如何作用这些字段,IP协议和路由选择协议,IP协议连接了硬件和软件层;
- 数据链路层:分组单位是帧 Frame,网络层从源到目的之间经过路由器路由数据报,将分组从一个结点移动到另一个结点,必须“依靠数据链路层的服务”,网络层将数据报下传给链路层,链路层沿着链路将数据传递给下个结点,下个结点链路层又将数据报上报给了网络层;链路层提供的服务取决于链路层的协议。链路层的分组为”帧“Frame,以太网,Wi-Fi,DOCsis;
- 物理层:在物理媒体上实现比特流的传输,物理层的任务是将链路层中的帧中的一个一个bit从一个结点移动到下一个结点,物理层协议于链路相关,也与物理介质相关,例如同轴电缆卡,光纤;
OSI、TCP/IP与五层参考模型
ISO国际标准化组织提出OSI,开发系统互联模型,理论模型,服务、协议、接口。
与之相对的TCP/IP参考模型有四层

应用层 表示层 会话层 传输层 网络层 链路层 物理层
- 五层参考模型

封装
应用层 报文 mesasge 传输层 报文段 segment = message + header 网络层 数据报 datagram = segment + header
链路层 帧 frame = datagram + header 物理层
- application-layer message — transport-layer segment — network-layer datagram — link-layer frame
- 链路层交换机实现第一层和第二层,路由器实现第一层到第三层,路由器能够实现IP协议,链路交换机不能,链路层交换机能够实现第二层地址,以太网地址;网络边缘的端系统可以实现一到五层,将复杂性较高的结构放在边缘;
- 封装 (encapsulation):在发送端,一个应用层报文(application-layer message) — 应用层报文+传输层首部=运输层报文段(transport-layer segment) — 网络层增加了源和目的端地址等网络数据报的首部,产生了网络层数据报 — 链路层增加链路层首部信息并创建链路层帧
- 每个分层:首部字段+有效载荷字段(header + payload field),有效载荷为上一层分组
1.6 攻击的网络
1.7 历史,分组交换的发展,专用网络和互联网络,因特网的发展
2. 应用层
2.1 网路应用程序体系结构
- 客户 - 服务器体系结构 client-server architecture 如Web应用,客户之间并不直接通信
- P2P结构, per to per architecture,对于服务器有最小依赖,“对等方”在主机间直接通信,p2p特性,自扩展性;
2.1.1进程通信
- 进行通信的实际是进程
- 运行在不同端系统上的进程,通过跨越计算机网络交换报文(message)而相互通信;
- 进程通过“套接字” socket的软件接口向网络发送报文和从网络接受报文,Socket下面使用运输层TCP或UDP协议,套接字也称为“网络程序编程接口”,套接字对运输层仅仅能 1.选择运输层协议 2.设定运输层参数如最大缓存,最大报文长度等。套接字是应用层和运输层之间的接口
- 开发者选择了运输层协议,应用程序就建立在由该协议提供的运输层服务至上;
- 进程寻址,“IP地址”来标识主机地址,“端口号Port”来表示主机中的进程,从而定位到通信的进程;
2.1.2可供应用程序使用的运输服务
- 可靠数据传输:分组交换机的缓存溢出导致的分组丢失,可靠数据传输(reliable data transfer),运输层协议向应用程序提供进程到进程的可靠数据传输
- 吞吐量:两个进程之间,可用吞吐量就是发送进程到接收进程交付比特的速率,会话会共享沿着网络路径的带宽,可用吞吐量会随着时间波动,运输层协议能够以某种特定的速率提供确保的可用吞吐量;具有吞吐量要求的应用程序为”宽铭感应用”,“弹性应用”是或多或少的利用可用吞吐量;
- 定时:运输层协议保障提供数据传输的总时延小于一个特定值;
- 安全性:运输层协议保障加密进程发送的数据
2.1.3运输服务
- TCP/IP网络中两个运输层协议,TCP和UDP
TCP服务
- TCP服务模型包括面向连接服务和可靠数据传输服务
- 面向连接服务:连接的三次握手,握手完成后,TCP连接就在两个进程的套接字之间建立了。四次分手
- 可靠的数据传输服务:TCP,会无差错、按照顺序交付所发送的数据,当App的一端将字节流传进套接字是,能够依靠TCP将相同的字节流交付给接收方的套接字,没有字节的丢失和冗余;
- 拥塞控制机制,在网络发送拥塞时,TCP的拥塞控制机制会抑制发送进程;或使每个连接达到公平共享带宽的目的;
- TCP UDP 不提供任何加密机制,安全套接字,SSL secure sockets layer;SSL是对TCP运输协议的加强,这样的安全强化是在应用层实现的(很容易);SSL有独立的一套SOCKET API
UDP服务
- 轻量级运输协议,提供最小服务,UDP是无连接的,提供一种不可靠的数据传输服务;
- UDP不保证报文到达接收方进程,到达的数据有可能是乱序到达;
- UDP没用拥塞机制,发送端可以使用UDP选定任何速率向下层注入数据;
运输协议不提供的服务
- 不能提供定时和带宽保证;
- 网络语音,以UDP作为主要运输协议,TCP作为当UDP流量被防火墙阻挡后的备选方案;
2.1.4应用层协议
- 应用层协议定义了
交换的报文类型,如请求报文和响应报文 报文语法 字段含义 进程何时及如何发送报文,报文的响应规则
HTTP 超文本传输协议,公共域的RFC SMTP 简单邮件传输协议
2.2 Web和HTTP
2.2.1HTTP
- 一个客户程序和一个服务器程序,运行在不同的端系统中,通过交换HTTP报文进行会话;HTTP定义了报文格式,已经报文的交换方式;
- 术语
Web页面 webpage 对象 object
- HTTP定义了web客户端向服务器请求页面的方式;
- HTTP使用TCP运输层服务,客户向他的套接字发送http报文,并从套接字接收响应报文;
- HTTP服务每次发送报文,都会将报文通过套接字交给TCP服务,HTTP协议不用担心数据的丢失和乱序问题,分层体系结构的最大优点;
- HTTP服务器不保存每次客户访问的信息,是一个“无状态协议“ stateless protocol
非持续连接和持续连接
- 非持续连接:每个请求是经过每次的单独的TCP连接发送,每次发送报文新建TCP连接
- 持续连接:所有的请求以同一个的TCP连接发送;
- HTTP既能使用非持续,也能使用持续连接,默认方式是使用持续连接,可以配置成非持续
非持续连接的HTTP
- 每个TCP连接只传输一个请求报文和一个响应报文;
- 往返时间: Round-Trip Time RTT,一个短分组从客服到服务器,再返回客户端所花费的时间;
- RTT:分组传播时延,分组传输时延、排队时延、处理时延
- 三次握手,客户向服务器发起一个TCP连接,客户向服务器发送一个小的TCP报文段,服务器用一个小TCP段作出确认和响应,最后客户向服务器返回确认(此时客户结合这部分发送一个http请求报文,一旦该报文被服务器接收,服务器就在该TCP连接上发送HTML文件);
- 采用非持续连接经受双倍的RTT交付延迟,第一个RTT用于创建TCP,第二个RTT用于请求和接受对象。值得注意的是,三次握手的第三次同时在请求。
持续连接的HTTP
- 非持续中,每个TCP都需要在服务器中分配TCP的缓冲区和保持TCP变量,给服务器带来较大负担,而且每个对象都需要经受两倍的RTT交付时延;一个RTT用来创建TCP连接,一个用来请求和接收对象;
- HTTP的默认模式是使用带流水线的持续连接,服务器在发送响应后保持TCP连接打开,同一个客户和服务器的后续请求和响应报文通过相同的TCP连接进行;服务器可以以流水线的方式一个接一个的发出对象的请求,不必等待回答;超时后HTTP服务器就会关闭连接;
2.2.2HTTP报文格式
请求报文
使用ASCII编写,最少一行,最后一行附加一个换行符;
- 请求行,后续叫做首部行 【方法字段】【URL统一资源定位】【HTTP版本】
1
2
3
4- 方法字段: GET POST HEAD PUT DELETE
- 首部行:HOST指明了对象所在主机,Web代理高速缓存所要求的
- Connection:close 要求服务器在发送完被请求对象后关闭这条连接
- User-agent:用户代理,不同的agent表示不同的设备或者浏览器。Mozilla标准绝大部分使用GET方法
POST报文仍然可以向服务器请求对象,表单的请求报文不是必须使用POST方法;
HEAD方法和GET方法类似,但是服务器不返回请求对象;
PUT方法多用于上传路径的服务
DETELE方法允许用户删除服务器上的对象
响应报文
状态行status line,协议版本+状态码+状态信息
首部行 header line
实体行 entity body 实体部分是报文的主要部分,包含了对象本身;
Connection:close 表示告诉客户,发送完报文后服务器将关闭TCP连接
Date:响应报文的时间
Server:Server类型和版本
Last—Modified:对象的最后修改时间
Content-Length:被发送对象的字节数
Content-Type:内容类型
常见短语和状态码
200 OK:请求成功301 Moved Permanently:请求的对象被永久转移了400 Bad request:请求不能被服务器理解404 Not Found:请求的对象不在服务器505 HTTP Version Not Supported服务器不支持请求报文使用的http协议版本
2.2.3cookie
HTTP服务是无状态的,cookie允许站点对用户进行跟踪;包含以下四个部分
- HTTP响应报文中包含一个cookie首部行 - HTTP请求报文中的一个cookie首部行 - 用户系统中保留一个cookie文件 - web站点后端数据库From:alice@crepes.fr To:bob@hamburger.edu Subject:Searching for the meaning of life1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32- Set-cookie首部识别码可以确定一个用户,在站点上每次访问的路径,跟踪用户的活动;
- **过程:在用户首次访问网站时,网站产生一个唯一识别码并保存在web站点后端数据库,接下来Web服务器把包含该识别码的报文传给用户,用户的浏览器收到报文后,将该识别码记录在浏览器的cookie文件中,这条记录包含服务器的主机名和识别码。当用户后面再次浏览该网站时,用户查询到目标服务器和识别码对应,就将识别码加入到http请求报文中。这样网站就可以跟踪用户的活动。**
### 2.2.4Web缓存
- Web cache & proxy server 也叫代理服务器
- 代表初始的web服务器来满足http请求的网络实体
- 有自己的磁盘空间用来存储最近保存过的对象的副本
- **过程:浏览器创建一个到web cache的tcp连接,并向web cache发送HTTP请求,Web缓存对对象做检查,有则直接返回给浏览器,无则与对象的初始服务器建立TCP连接。Web缓存器在这个TCP连接上发送HTTP请求,初始服务器Web cache进行响应,接收到对象的web cache会在本地存储一份副本,并向浏览器发送对象,web cache和浏览器也是TCP连接;**
- 通常由ISP提供,比如一所大学可能在校园网上安装一台WEB缓存器。
- 内容分发网络 Content Distribution Network CDN,CDN在地理位置上安装了很多缓存器,使得大量流量本地化
### 2.2.5条件GET方法
- **过程:web缓存器在收到报文后记录一个时间,在下次向服务器请求时带上这个时间并询问服务器这个页面是否在这个时间之后被修改,若修改,则发送新的报文给缓存器,若无,则回复 `304 not modified`**
- 请求使用 GET method
- header line: “If-Modified-Since:”
## 2.3 电子邮件
### 2.3.1SMTP
- **过程:发送方调用邮件代理程序并提供接收方的邮件地址然后指示用户代理发送该报文,用户代理将报文发送给`发送方的邮件服务器`,在那里报文进入报文队列中,运行在发送方的邮件服务器的SMTP客户端发现了这个队列中的报文,(25号端口)创建一个到`接收方的邮件服务器`的TCP连接,在经过一些初始的SMTP握手后,SMTP客户通过该TCP连接发送报文,接收方的邮件服务器SMTP服务器端接收到了该报文,邮件服务器将报文放入接收方的邮箱之中。接收方调用用户代理阅读该报文。**
- 需要值得注意的是只有`发送方的邮件服务器`和`接收方的邮件服务器`,SMTP一般不使用中间服务器。如果接收方的邮件服务器没有开机,那么发送方的邮件服务器在后续会进行多次尝试。
### 2.3.2与HTTP对比
| | 相同 | 不同 |
| ---- | ---------------------------- | ------------------------------------------------------------ |
| HTTP | 都是一台主机向另一台发送信息 | 1、HTTP是一个拉协议;2、HTTP没有7比特ASCLL字符限制;3、HTTP把每个对象封装到一个报文中 |
| SMTP | 都是一台主机向另一台发送信息 | 1、SMTP是一个推协议;2、SMTP只能发送7比特的ASCLL字符;3、SMTP把所有对象封装到一个报文中 |
### 2.3.3邮件报文格式EstimatedRTT = (1- α)· EstimatedRTT + α · SampleRTT DevRTT = (1-β) · DevRTT + β · |SampleRTT - EstimatedRTT|1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
### 2.3.4邮件访问协议
- 之前我们默认是需要登录去访问邮件服务器的,而今天,邮件访问使用了一种**`客户-服务器体系结构`**,即用户使用桌面客户端来阅读电子邮件。
- 如果邮件服务器运行到用户设备上,那么保持持续在线是一件很困难的事。所以通常用户运行代理程序,而他访问总是开机的共享服务器上的邮件服务器。但是这又引发了一个问题:**接收方是如何通过本地的代理程序来阅读程序的呢?(SMTP是一个推协议,所以无法使用SMTP来得到)**
- 上面这个问题的解决用到了一些特殊的邮件协议:**`POP3`和`IMAP`以及`HTTP`**
- POP3:**过程分为三个阶段,第一阶段特许,服务器鉴别用户;第二阶段事务处理,用户代理取回报文,同时还可以选择对报文进行删除标记等;第三阶段更新阶段,即客户发出了quit命令之后,断开POP3连接,服务器删除被标记的报文**
- IMAP:**POP3无法为用户创建远程文件夹,也无法指派文件进入文件夹,所以IMAP应运而生,IMAP可以在邮件服务器接收邮件时与收件夹自动关联,后续在用户代理操作时可以指派文件夹,同时IMAP还可以选择只读取报文的首部,就可以避免一些下载不必要的大邮件。**
## 2.4 DNS,域名解析服务
工作机理:浏览器向用户DNS客户端发送主机名(gethostbyname),DNS客户端从缓存中查找,找不到向网络发送一个DNS查询报文,DNS请求和回答报文都是用UDP数据报经过53端口发送,DNS客户端将映射结果返回给调用的程序;
### 2.4.1DNS提供的服务
- 从主机名到ip地址转换目录服务。
- DNS通常是其他应用层协议所使用的,它提供如下服务:
- 从主机名到ip地址转换目录服务
- 主机别名
- 邮件服务器别名
- 负载分配
### 2.4.2DNS工作机理概述
#### 分布式、层次数据库
- 没有一台DNS服务器能够囊括全球域名,因此需要大量的DNS服务器,大致来说有三种:根DNS服务器,顶级域DNS服务器(tld),权威DNS服务器,还有一类: 本地DNS服务器,不过严格来说他不处于这个层次中
- **过程:客户访问一个网址,首先向他的本地DNS服务器查询,本地DNS服务器将该报文转发到根DNS服务器,根DNS服务器再向本地DNS服务器返回负责这部分顶级域的tld-DNS服务器的ip地址列表,本地DNS服务器再向tld发送查询报文,tld再发送相关权威DNS服务器的ip地址,最后本地服务器再向权威服务器的ip发送报文,最后权威DNS服务器给出要访问的网址的ip地址,最后终于得到了ip地址**
#### DNS缓存
- DNS服务器会缓存IP/主机名的信息,在查询过程中的一级DNS服务器存储了这个ip就可以直接找到。
### 2.4.3DNS记录 DNS报文
- 资源记录:NAME|VALUE|TYPE|TTL
- NAME和VALUE的值主要取决于TYPE
- TYPE分为A(主机名-ip)、NS(域如auswitz.top-知道如何获取该域主机ip的权威服务器)、CNAME(规范主机名-别名)、MX(邮件服务器的别名-规范主机名)
- TTL:该记录的生存时间
### 2.4.4DNS脆弱性
- 针对DNS的DDos分布式拒绝服务带宽洪泛攻击,将大量分组发送到DNS服务器,以至于合法的分组得不到回答
- 但是,总而言之,DNS已经显示了惊人的鲁棒性,迄今为止,没有一个攻击有效的妨碍了DNS服务。
## 2.5 P2P
## 2.7 TCP 套接字编程
- 服务器端应用和客户端应用使用统一的RFC标准,就能实现交互操作;
- 选择TCP还是UDP,TCP面向连接并提供两个端系统之间数据流动的可靠字节流通道,UDP无连接,发送独立的分组,不对交付进行任何保证;
### UDP套接字
- 发送进程为分组附上目的地址,为主机的ip地址和目的地套接字的端口号,发送方的原地址也是由套接字端口号和源主机的IP地址组成,该源地址也要附着在分组之上;将源地址附在分组上的操作并不是由UDP应用程序代码所为,而是由底层操作系统自动完成;
- PG108
### TCP套接字
- 1. UDP,TCP服务器在客户端开始发出接触前,必须已经准备好,服务器进程必须处于运行的状态;
- 客户进程创建一个TCP套接字,向服务器进程发起一个TCP连接,客户端套接字知道拿过来主机的IP和端口号,生成套接字后客户发起一个三次握手创建与服务器的TCP连接,发生在运输层的三次握手对客户和服务器是完全透明的;
- 欢迎套接字:客户与服务器通信的起始接触点,欢迎套接字处进行三次握手
- 连接套接字:服务器侧为每个客户通信生成的套接字,连接套接字表示连接成功
- PG112
# 3. 运输层
## 3.1 运输层服务
- 运输层协议为运行在不同主机之间的应用程序提供了**逻辑通信**的功能 Logic communication
- 运输层从应用程序接受报文并转化成**”报文段“**,实现方式是将报文划分成较小的块,并为每块加上一个运输层首部以生成运输层报文段;
- **报文分块** – **添加首部** – **生成报文段** – 运输层将这些报文传递给网络层,网络层将其封装成数据报分组并向目的地发送;
- 路由器只会作用于网络层字段,不会检查封装在该数据报的运输层报文段和字段;运输层则处理接受到的报文段,使该报文的数据为接受应用程序使用;
### 运输层和网络层的关系
- 网络层提供了主机之间的逻辑通信
- 运输层提供了进程之间的逻辑通信
- 运输层协议只在端系统中工作;对报文在网络核心中如何移动不做任何规定;
- 不同的运输层协议为应用程序提供不同的服务模型
- 底层的网络层协议不可靠,分组交换机会发送分组丢失等,但是运输层协议仍然能够为应用程式提供可靠的数据传输;
### 概述
- 运输层分组:报文段 segment TCP:报文段 UDP:数据报 网络层:数据报
- IP的服务模型:**尽力为交付服务** best-effort delivery service,尽最大努力交付,但是不做任何确保,不确保报文段的交付、不确保报文段的按序交付、不确保报文段中的数据的完整性
- IP:不可靠服务
- TCP UDP的基本责任是:将两个端系统之间的IP的交付服务扩展为运行在端系统上的两个进程之间的交付服务;
- 主机间的交付扩展到进程间的交付: **运输层的多路复用** 与 **多路分解** (transport-layer multiplexing, demultiplexing)
- **进程和进程的数据交付**和**差错检查**是两种最低限度的运输层服务
### TCP概述
- 可靠数据传输 reliable data transfer
- 流量控制
- 序号
- 确认
- 定时器
- TCP能够正确的、按序的将数据从发送进程交付给接收进程
- 拥塞控制 congestion control
- 提供给调用它的应用程序的一种服务,也是提供给因特网的一种服务,防止任何一条TCP连接用过多的流量来淹没主机之间的链路和设备交换
- TCP调节流量速率来让每个连接平均的共享链路带宽
- UDP的流量是不可调节的
## 3.2 多路复用与多路分解
### 多路分解
- 接收主机的运输层将数据交付给套接字,
- 每一个套接字都有一个唯一的标识符
- 主机将到达运输层的报文段定向到适当的套接字,运输层会检查报文字段,标识处接收套接字,进而将报文定向到套接字;
- 多路分解:将运输层报文段的数据交付给正确的套接字
- 多路复用:源主机将不同套接字数据封装上首部信息从而生成报文段,将报文段传递到网络
### 工作方式
- 要求: 1. 套接字有唯一的标识符 2. 每个报文段有特殊的字段来指示该报文要交付给的套接字
- 源端口号字段+目的端口号字段 一个端口好是16bit (source port number field + destination port number field)
- 每个套接字都能分配一个端口号
- 当报文到达主机时,运输层检查报文中的**目的端口号** ,并将报文段定向到相应的套接字
### 端口
- 0~1023的端口号为 well-known port number 保留给已知应用
- 0~65535
- 16bit
### 无连接的多路复用和多路分解
- 对于UDP协议,运输层会创建运输层报文段,包括源端口,目的端口和数据
- 接收主机的UDP服务会设别目的端口,并将数据交给对应的套接字
- UDP的套接字:一个二元组来标识,保护一个目的IP和一个目的端口号
- UDP使用二元组中的两个值,来将报文定向到相应的套接字上
- 来自不同源地址的UDP报文,只要目的地址和目的IP相同,那么报文就会到达同一个套接字
- UDP套接字中包含源ip地址和源端口号,用于接收端进行回包的时候从报文中提取源地址和源端口作为目的地址和目的端口
### 面向连接的多路复用和多路分解
- TCP套接字是一个**4元组** 源地址 源端口 目的地址 目的端口
- 到达主机的报文,TCP服务会是使用全部4个值来将报文段定向到相应的套接字
- 4元组中任意一个不同,报文都会到达不同的套接字
- 服务器主机可以支持很多并行的TCP套接字,每个套接字与一个进程相联系,并由4元组来标识套接字;当一个TCP报文到达主机时,所有4个字段都将会用来定向报文到相应的套接字;
### Web服务器与TCP
- Web服务器具有多个新连接套接字的新线程,任意时间内会有不同标识的套接字连接到相同的进程中;线程管理的套接字可以接收或者发送HTTP请求和响应
## 3.3 无连接运输-TCP
- 运输层必须最低限度的提供一种 复用/分解 的服务
- UDP协议的功能:多路复用,多路分解,差错检测
- UDP发送方和接收方之间没有握手,UDP是无连接的
- 选择UDP的原因依据:
- 时间和数据:不希望过分的延迟发送报文,且能容忍一定的数据丢失、
- 无需建立连接:UDP无连接时延
- 无连接状态:UDP无需维护连接状态,无需跟踪参数,无拥塞控制机制
- 分组首部开销小:源端口、目的端口、校验和、数据大小
- RIP路由表选择协议使用UDP,更新的丢失会被最新的更新替代,可以容忍数据丢失
- SNMP简单网络控制协议,对于处于重压下的网络,对于可靠的且有拥塞控制的协议无法完成对网络的实时管理;
- UDP中缺乏拥塞控制,会导致UDP的接收方和发送方之间的高丢包率,并有可能会挤垮了TCP会话;
- 使用UDP也可以实现可靠的数据传输,需要在应用程序自身建立可靠性机制,在应用程序中进行开发,可以不依赖TCP的服务和拥塞控制;
### UDP的报文段结构
- 首部包含四个字段每个字段由2个字节组成,每个字节是8个bit
- 每个字段包含16个比特Bit
| 16bit | 16bit |
| ------------------------- | ----------------------------------------------- |
| 源端口 | 目的端口 |
| UDP报文首部和数据的总长度 | 校验和,对UDP报文段中的所有16比特字的和进行反码 |
| 报文数据 | 报文数据 |
### UDP校验和
- **校验和的值**: 发送方的所有16比特字的和,进行反码运算,且相加溢出需要回卷
- 接收方将所有16比特字及校验和相加,无差错的情况下相加结果全为1
- 链路层路由协议及以太网协议也都提供了差错检测,传输层的差错检测存在的意义就是因为不能保证每一条链路都使用了差错检测的协议;这既是无法确保链路的可靠性;
- **端到端原则**: 必须基于端到端实现功能,因为相比在较高级别实现这些功能的代价,在较低级别上实现可以是冗余或者几乎无价值的;
- UDP对检验出的受损报文段:1. 直接丢弃 2. 交给套接字并向应用程序发出**警告**
## 3.4 可靠数据传输原理
- 可靠数据传输为上层实体提供的服务抽象: **数据可以通过一条可靠的信道传输**
- 传输数据不会受损例如数据bit从0变为1或者从1变为0,且数据按照发送顺序交付
- TCP的下层不可靠,TCP在不可靠的IP协议端到端网络层上实验可靠数据传输,且**可靠数据传输协议**下层可能是一条或者多条物理链路
### 可靠传输
- 发送方:rdt_send()函数, 数据接收:rdt_rcv(),数据交付高层服务:deliver_data() 交换控制分组;udt_send()
- 单向数据传输 unidirectional data transfer
- 双向数据传输 bidirectional data transfer 全双工数据传
### 3.4.1 构造可靠数据传输
#### 1. rdt1.0
> 有限状态机 Finite-state Machine,FSM
>
> 有限状态机是一种用来进行对象行为建模的工具,其作用主要是描述对象在它的生命周期内所经历的状态序列,以及如何响应来自外界的各种事件。
>
> [有限状态机-外部文档](https://www.jianshu.com/p/5eb45c64f3e3)
| rdt1.0 - 发送端 | {action} |
| ------------------ | ----------------------------------------- |
| 等待上次应用的调用 | rdt_send(data) |
| | packet = make_pkt(data); udt_send(packet) |
| rdt1.0 - 接收端 | {action} |
| ------------------ | ----------------------------------------- |
| 等待来自下层的调用 | rdt_rev(packet) |
| | extract(packet, data); deliver_data(data) |
- 发送方和接收方都有各自的FSM,上图FSM各自只有一个状态
- 发送端:rdt的发送端只通过rdt_send(data)事件接收来自较高层的数据,然后生成一个包含数据的分组,并将分组发送到信道中;事件由上层应用的过程调用产生;
> 过程调用和系统调用
- 接收端:rdt通过rdt_rcv(packet)事件从底层信道接收一个分组,然后从分组中取出数据extract,并将数据上传给高层deliver;rdt_rcv事件由较为底层的协议过程调用产生
#### 2. rdt2.0
- 肯定确认 (positive acknowledgement) 否定确认 (negative acknowledgment),控制报文使得接收方可以让发送发知道哪些内容被正确接收,哪些内容接收有误需要自动请求重传;
- **自动重传协议** Automatic Repeat reQuest ARQ
- 自动重传协议
需要的支持
- 差错检测,分组**检验和**字段
- 接收方反馈,“肯定确认” ACK,“否定确认” NAK
- 重传,接收方收到有差错的分组时,发送方收到反馈后将进行重传
| 发送方 | |
| -------------------- | ------------------------------------------------------------ |
| STATE | ACTION |
| 等待来自上层的调用 | rdt_send(data) |
| | sndpkt = make_pkt(date, checksum); udt_send(sndpkt) |
| 等待ACK或NAK | rdt_rcv(rcvpkt) && isNAK(rcvpkt); udt_send(sndpkt) #接收到NAK分组并重发sndpkt分组 |
| ⬆ # 返回等待调用状态 | rdt_rcv(rcvpkt) && isACK(rcvpkt) # 接收到ACK确认分组,不再做其他操作,状态返回“等待过程调用” |
| 接收方 | |
| ------------------------------ | ------------------------------------------------------------ |
| STATE | ACTION |
| 等待来自下层的调用(过程调用) | rdt_rcv(rcvpkt) && corrupt(rcvpkt) |
| | sndpkt = make_pkt(NAK); udt_send(sndpkt) #检验后发现分组数据受损,给发送方回发NAK分组 |
| | rdt_rcv(rcvpkt) && notcorrupt(rcvpkt) |
| | extract(rcvpkt, data); deliver_data(data); sndpkt = make_pkt(ACK); udt_send(sndpkt) #检验后发现分组数据无损,将数据提交给高层应用后,给发送方回发ACK分组 |
- 发送方有两种状态,等待上层过程调用状态和等待ACK或者NAK状态,**当发送方处于**
- **行rdt_send()调用,发送方只有收到确认ACK分组后,才会发送新的数据**
- 这样的等待协议为 **停等** 协议 stop-and-wait
- 接收方的FSM只有一个状态,当分组到达时,接收方检验分组是否受损,要么回答一个ACK要么回答一个NAK;
- 解决ACK或者NAK分组受损导致发送方无法明确分组是否被正确接收的方法是:引入新字段,**分组编号**,就是发送数据的分组**序号 sequence number**
#### rdt 2.1 2.2
- 新增,接收方收到受损分组发送否定确认,发送方收到受损返回分组则重新发送分组
- 接收方包括一个由ACK报文所确认的分组序号,make_pkt()中包含ACK 0 ACK1
- 发送方必须检查接收到的确认分组中的序号
#### 3. rdt3.0 具有比特差错的丢包信道的可靠数据传输
> 检测丢包和丢包后的action
- 当前已经包含的: 检验和、序号、ACK分组、重传机制
- 发送方等待超时,如果等待足够长的时间没有收到接收方的响应,便对该分组进行重传
- 等待时间: 发送方与接收方之间的一个往返时延(传输时延,传播时延,排队时延) + 接收方处理一个分组的时间, 实践中,发送方明智的选择一个确定的时间值作为等待时间
- 如果一个分组经历了比较长的时延,但是并没有丢包,发送方也会重传该分组,这样的情况下接收方就会 **“冗余数据分组**,分组序号可以解决冗余数据分组的问题
- 过度延时或者分组丢失都会导致重传
- 倒计数定时器 countdown timer, 用于给定时间过期后,中断发送方;
| 发送方 | |
| -------------------- | ------------------------------------------------------------ |
| 等待来自上层的调用 0 | rdt_send(data) |
| | sndpkt = make_pkt(0, data, checksum); udt_send(sndpkt); start_timer; |
| 等待ACK 0 | rdt_rcv(rcvpkt) && (corrupt(rcvpkt) \|\| isACK(rcvpkt, 1)) # 等待响应分组,1. 下层过程调用rdt_rcv 2. 如果检验后数据受损 或 获得的确认包序号不是当前0序号 则保持当前状态 |
| | timeout; udt_send(sndpkt); start_timer; #如果出现超时(数据丢失或者网络延时),则重新发送序号为0的分组,并启动新的timer,发送后依然保持当前等待0响应的状态 |
| ⬇ 到下一状态 | rdt_rcv(rcvpkt) && notcorrupt(rcvpkt) && isACK(rcvpkt, 0)); stop_timer; #当在该状态下收到响应分组,调用rdt_rcv函数后,检验数据无损,且当前响应分组的序号与当前等待状态序号一致,此处为0,则进入下一状态 |
| 等待来自上层的调用1 | rdt_send(data) |
| | sndpkt = make_pkt(1, data, checksum); udt_send(sndpkt); start_timer; |
| 等待ACK 1 | rdt_rcv(rcvpkt) && (corrupt(rcvpkt) \|\| isACK(rcvpkt, 0)) # 等待响应分组,1. 下层过程调用rdt_rcv 2. 如果检验后数据受损 或 获得的确认包序号不是当前1序号 则保持当前状态, 继续等待正确响应分组 |
| | timeout; udt_send(sndpkt); start_timer; #如果出现超时(数据丢失或者网络延时),则重新发送序号为1的分组,并启动新的timer,发送后依然保持当前等待0响应的状态 |
| ⬇ 到下一状态 | rdt_rcv(rcvpkt) && notcorrupt(rcvpkt) && isACK(rcvpkt, 1); stop_timer; #当在该状态下收到响应分组,调用rdt_rcv函数后,检验数据无损,且当前响应分组的序号与当前等待状态序号一致,此处为1,则进入下一状态 |
| | |
| 接收方 | |
| ------------------------------- | ------------------------------------------------------------ |
| STATE | ACTION |
| 等待来自下层的调用0(过程调用) | rdt_rcv(rcvpkt) && (corrupt(rcvpkt) \|\| has_seq1(rcvpkt)) ; sndpkt = make_pkt(NAK, 0, checksum); udt_send(sndpkt) #下层调用,检验数据是否受损, 检测分组序号,当数据受损或序号为1时,继续保持该状态等待下层调用0, 并发送0的NCK响应 |
| ⬇ 到下一状态 | rdt_rcv(rcvpkt) && corrupt(rcvpkt) && has_seq0(rcvpkt); extract(rcvpkt, data); deliver_data(data); sndpkt = make_pkt(ACK, 0, checksum); udt_send(sndpkt) # 接收分组,解出数据,校验数据无损且分组序号为0,则将数据提交给上层应用,并向发送方响应序号为0的ACK,当前状态转移到等待下层调用序号1 |
| 等待来自下层的调用1(过程调用) | rdt_rcv(rcvpkt) && (corrupt(rcvpkt) \|\| has_seq0(rcvpkt)) ; sndpkt = make_pkt(NCK, 1, checksum); udt_send(sndpkt) #下层调用,检验数据是否受损, 检测分组序号,当数据受损或序号为1时,继续保持该状态等待下层调用0, 并发送0的NCK响应 |
| 返回初始状态 | rdt_rcv(rcvpkt) && corrupt(rcvpkt) && has_seq1(rcvpkt); extract(rcvpkt, data); deliver_data(data); sndpkt = make_pkt(ACK, 1, checksum); udt_send(sndpkt) # 接收分组,解出数据,校验数据无损且分组序号为1,则将数据提交给上层应用,并向发送方响应序号为1的ACK,返回初始状态 |
### 3.4.2 流水线可靠传输协议
- rdt3.0的停等协议有着非常低的发送利用率 每个分组到达接收方后返回ACK的延时为一个RTT
- 解决方法:不使用停等协议等方式运行,允许发送方发送多个分组而无需等待确认;
- 流水线 pipelining
带来的影响
- 必须增加序号范围,每个分组必须有一个唯一的序号
- 协议的发送方和接收方两端必须**缓存多个分组**
- 序号范围和缓冲 取决于数据传输协议如何处理丢失、损坏、延时过大的分组;流水线的差错恢复的方法: **回退N步 (Go-back-N GBN)**,**选择重传 (Seletive Repeat, SR)**
### 3.4.3 回退N步
> | | | | | | | | | | | | | | | | | | | | | | | |
> | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
> | | | | | | | | | | | | | | | | | | | | | | | |
>
> base nextseqnum
>
> —–窗口长度—-
>
> 窗口到nextseqnum前是已发送但未确认分组,nextseqnum后是未发送分组
- 已经被发送但是还没有确认的分组的许可序号范围可以被看成一个在序号范围内的N的**窗口**;
- N为**窗口长度 window size**, GBN协议也被称为**滑动窗口协议 sliding window protocol**
- 运输层分组首部:分组序号,szie为k比特,则序号范围=[0, 2^k -1],序号使用模2^k运算;
- TCP的序号按照字节流中的字节计数
- GBN响应的三种类型
- 上层调用 rdt_send(),当前窗口未满时(判断是否已经有N个已经发送但是未被确认的分组),产生一个分组并发送,并更新变量;如果窗口已满,发送方需要将数据返回给上层,上层会稍等再试;
- 收到一个ACK,在GBN中,对序号为n的分组采用**累计确认 cumulative acknowledgment** 的方式,表明接收方已经正确接收n及n在内的所有的分组
- 超时事件,出现丢失和时延过长分组的情况下,发送方重传所有已经发送但是还未确认的分组,也就是重传当前窗口中的所有分组;
- GBN中,接收方,序号为n的分组被**按序正确接收**则接收方发送一个ACK,其他情况下接收方丢弃分组,并为最近按序接收的分组重新发送ACK;
- 如果序号为k的分组已经交付给上层,则证明k-1个分组都已经交付
- 因为数据必须按序交付,如果接收方等待分组n但是却收到了分组n+1,接收方会直接丢弃分组n+1,因为如果不丢弃会导致发送方重传,因此只需丢弃n+1,优点是接收缓存简单,接收方无需缓存失序分组;
- 发送方需要维护窗口的上下边界及nextseqnum在该窗口的位置,接收需要维护下一个按序接收的分组序号;且保存在expectedseqnum;
> 基于事件编程 event-based programming
### 3.4.4 选择重传
- 选择重传 SR 协议通过让发送方仅重传那些它怀疑在接收方出错(丢失、受损)的分组
> | | | | | | | | | | | | | | | | | | | | | | | |
> | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
> | | | | | | | | | | | | | | | | | | | | | | | |
>
> base nextseqnum
>
> —–窗口长度—-
>
> nextseqnum前包含 已经确认的分组 和 已发送未确认分组
>
> nextseqnum之后是 未发送分组
- 发送方和接收方的序号空间
- 发送发
- 从上层接收数据,序号位于窗口内,将数据打包发送,如果不在窗口内,则将数据缓存或者将数据返回给上层;
- 超时,每个分组有自己的逻辑定时器,超时发生后只能发送一个分组,使用一个硬件定时器模拟多个逻辑定时器;
- 收到ACK,发送方收到ACK且判断在窗口内时,SR发送方将分组标记为“已接收”;当收到的序号等于send_base时,则base向前移动到**“最小序号的未确认处”**,如果序号为窗口内未发送分组,则发送这些分组
- 接收方,将确认每个正确接收的分组,失序的分组将被缓存直到所有丢失分组都被收到为止;所有分组被收到后,将分组按序交付给上层;
- 序号在[rcv_base, rcv_base + n -1]内的分组被正确接收,收到的分组落在接收方的窗口内,选择ACK被会送给发送方;分组以前没有收到过,则缓存;分组序号为base序号,则触发该分组前的连续分组交付给上层;窗口向前移动并按照编号交付分组;
- 序号在[rcv_base, rcv_base + n -1]内的分组被正确接收,此时,必须产生一个AC
- 接收方会重新确认(ACK)已经收到过的序号小于当前窗口base的分组;
- SR中接收方和发送方的窗口不总是一致的;

- 对于SR协议,窗口的长度必须小于或者等于序号空间大小的一半;
- Page153,对于发送方窗口序号为0,1,2,3,0,1,2 窗口长度为3,接收方无法判断序号为0的分组是重传还是第五个分组的初次传输;此处序号空间是4,但是窗口size为3,导致协议无法工作;
##### 可靠数据传输机制总结
| 机制 | 说明 |
| --------------------------- | ------------------------------------------------------------ |
| 检验和 checksum | 检验分组数据bit是否受损 |
| 定时器timer | 用于分组丢失的情况下的超时重传,分组丢失或者ACK回复在链路中丢失,或者因为链路时延导致超时;重传可能会导致接收方的分组冗余 |
| 序号 sequence number | 对从发送方到接收方的数据按序编号,发送方可以按序交付数据给接收方,接收方通过序号检测数据是否受损或者丢失并向发送方回复;接收方还可以通过序号检测是否收到了冗余副本; |
| 确认 ACK | 接收方用于确认一个分组或者一组分组是否正确接收,携带被确认的分组的序号或者多个序号,确认可以逐个也可以是积累的; |
| 否定确认 NAK | 接收方用于回复发送方某一个序号的分组未正确接收,例如数据顺坏,携带被否定确认的分组的序号; |
| 窗口、流水线 sliding window | 发送方通过一次发送多个分组,不断更新窗口位置,接收方每次收到base序号的分组后,则将缓存中的分组交付给上层;窗口长度根据接收方 接收 和 缓存 报文的能力、网络拥塞程度来配置; |
- 通过假定一个分组在网络中“存活”时间不会超过一个最大的固定时间(最大分组寿命3分钟),来确保一个序号的分组都已经不再网络中,则可以重复使用该序号;对序号的重复使用会导致冗余分组和当前分组的混乱,所有重复使用序号的前提是必须保证网络中不再包含该序号的分组;
## 3.5 面向连接的运输:TCP
### 3.5.1 TCP连接
- 发送预备报文段,进行握手,以建立确保数据传输的参数,进而建立**“连接”**;
- TCP/IP Transmission Control Protocol/Internet Protocol,建立之初为单一的实体,后来将其分开为TCP和IP协议,存在于网络的不同层次
- 连接状态完全保留在两个端系统中,中间网络不会维持TCP连接,中间网络对TCP连接完全“视而不见”
- 全双工服务(full-duplex service);进程A和进程B可以同时发送数据;
- 点对点(point-to-point),单个发送方和单个接收方;
##### 连接的建立
- 客服进程、服务器进程
> clientSocket.connect((serverName, serverport))
- 两个进程之间发送了3个报文段,前两个不承载“有效载荷”,建立的过程被称为三次握手(three-way handshake)
- 客户进程通过套接字将数据传递给TCP服务,TCP将数据引导到发送缓存(send buffer);TCP从缓存中取出数据放入报文段并发送,取出数据受限于**最大报文段长度 MSS 1460byte**,最大链路层帧长度**最大传输单元 MTU**
- MSS指的是TCP报文段中的数据的最大长度;
- TCP为每一块数据加上**TCP首部**,从而形成多个TCP**报文段 TCP segment**,报文段被传给网络层,IP协议的服务将其封装在IP数据报中;然后IP数据报被发送到网络中;TCP的接收端有自己的接收缓存;
- 组成:一台主机上的缓存、变量、与进程连接的套接字,另一台主机上的缓存、变量、与进程连接的套接字
### 3.5.2 报文段 结构
- 32bit
| 32bit |
| :----------------------------------------------------------: |
| 源端口号 \| 目的端口号 |
| 序号 |
| 确认号 |
| 首部长度\|保留未用\|URG\|ACK\|PSH\|RST\|SYN\|FIN \| 接收窗口 |
| 检验和 \| 紧急数据指针 |
| 选项 |
| 数据 |
- **MSS限制了报文段数据字段的最大长度**,对于较大的文件,TCP会将文件划分成若干块进行处理
- 和UDP相同,首部包括了源和目的端口、检验和字段(checksum)
- 32bit的序号字段,32bit的确认号字段
- 16bit的接收窗口字段,用于流量控制,用于指定接收方愿意接收的字节数量
- 4bit的首部长度字段,典型长度为20byte
- 选项字段,可变长度用于协商MSS
- 6bit的标志字段 flag field
- ACK 用于确认报文段是否被成功接收,1 bit
- RST、SYN、FIN用于连接的建立和拆除,1bit
- PSH表示,是否立即将数据交付给上层,1bit
- URG表示,报文段中是否 ”存在“ 被发送端的上层实体置为”紧急“的数据
- 紧急数据指针字段用于指出紧急数据,存在时TCP会通知上层服务;16bit
##### 序号和确认号
- 一个报文段的序号(sequence number for a segment)是报文段的首字节的字节流编号;
> 例如MSS为1000,一个500 000字节的文件,TCP每个报文段的序号应该是:0,1000, 2000…
- **确认号**: 接收方填充进报文段的**确认号**为接收方等待发送方发送的数据流中下一个的字节;
- TCP只确认该数据流中至第一个丢失字节位置的字节,***TCP为 累计确认\*** (cumulative acknowledgement)
- 报文失序到达的处理选择:
- 接收方将直接丢弃失序报文
- 接收方保留失序的字节,并等待缺少的自己以填补间隔。实践中采用此方法
- TCP连接双方可以随机的选择初始序号,目的是防止同端口的先前已经断开的连接但是有报文段存在与网络中,可能会导致这个报文段被认为是新连接的报文段;
> Telnet 远程登录的应用层协议,运行在TCP之上的交互式应用;Telnet和ssh的区别是没有加密
>
> 回显:echo back
>
> telnet用例,Page160
- 捎带:服务器对来自客户数据的确认被装载在一个承载了服务器到客户数据的报文段中;
- TCP数据为空时,也会存在序号字段;
### 3.5.3 往返时间与超时
- TCP使用超时重传机制
- TCP使用 SampleRTT来预估 一次的RTT时间,TCP会维持一个平均值**EstimateRTT**,当获取到新的SampleRTT,计算加权平均值的方式如下:TimeoutInterval = EstimatedRTT + 4 · DevRTT1
2
3
4
5
6
7
8
9
> α参考值为0.125,β推荐值为0.25
>
> 指数加权移动平均
>
> 定义了DevRTT为SampleRTT到EstimatedRTT的偏离程度
- 考虑到SampleRTT的波动,超时重传的时间间隔1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 // 对每个路由结点x的算法 Initialization: for all destination y in N: Dx(y) = c(x,y) // 获取结点到网络中其他结点的距离向量(如果y和x不相邻,则初始化为正无穷) for each neighbor w: Dw(y) = ? for all for all destination y in N //初始化每个邻居结点w到每个结点y的距离向量 for each neighbor w: send distance vector Dx = [Dx(y): y in N] to w // 将当前结点x到其他结点y的距离向量发送给每个邻居结点 Loop wait //一直处于等待状态。等待结束的条件:1. 发现与当前结点相连的链路费用发生变化 2. 接收到邻居结点发送来的距离向量集合 for each y in N: Dx(y) = minv {c(x, v), Dv(y)} // 结点对收到的邻居结点的距离向量集合,x到y的最小费用是,x到邻居结点v+邻居结点v到y的距离向量的最小值,从所有邻居中找到这个最小值 if Dx(y) changed for any destination y send distance vector Dx = [Dx(y): y in N] to all neighbors // 如果当前链路有费用改变,则直接向邻居结点发送距离向量集合1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
- 初始推荐为1秒
##### 实践原则
- TCP的快速重传,收到对一个报文段的3个冗余ACK就可作为对**后面**报文段的一个隐式的NAK,从而在超时触发前就对报文段重传;
- TCP使用流水线,发送方在任意时刻都有多个已经发出但是还未被确认的报文段存在;
### 3.5.4 可靠数据传输
- 回顾:IP协议的不可靠,数据报可能会溢出路由器输出缓存,数据报达到目的地址乱序,数据报在传输过程中比特可能损坏;
- TCP是在IP的不可靠服务上创建的可靠数据传输服务(reliable data transfer service)
- 确保:进程从接收缓存中读取的数据流是无损坏、无间隔、非冗余、按序
#### 单一重传定时器简化描述
- 事件一,TCP从应用层接收数据,并将数据进行封装,报文段被发送给IP时,TCP启动**定时器**,这里定时器的timeout时间是前面提到的TimeoutInterval,由EstimatedRTT和DevRTT计算得出
- 事件二,发送方处理来自接收方的ACK(这里的ACK被包含数据的报文段捎带),TCP将ACK确认号与窗口变量SendBase进行比较,因为累计确认,ACK的值确认了该值前的所有序号的数据都已经正确接收,发送方更新SendBase后,TCP需要重启定时器;
##### 情况描述,A为发送方,B为接收方
1. A发送序号为92的长度为8的报文段,等待B的确认号为100的报文段;B发送给A的报文丢失,A超时重发,B收到了已经收到的报文段,B中的TCP服务将丢弃报文段中的字节;
2. A发送序号为92的长度为8的报文段和序号100长度为20的报文段,两个报文段完好到达B,B为每个报文发送一个确认,第一个确认号为100,第二个确认号为120,两个确认报文段在超时前未到达B,A将重传序号为92的报文段,并重启定时器,120的ACK报文段到达,第二个报文段就不被重传;
3. 和2中情况一样,100的确认号的报文段在网络中丢失,120的确认号的报文段到达A,A确认199及之前的所有字节都已经正确接收,A不会重传任何一个报文段;
#### 超时间隔加倍
- 超时事件发生,TCP重传具有最小序号的还未被确认的报文段;每次重传将下一次的超时时间间隔设置为先前值的2倍,而不是使用计算值,定时器在收到上层数据或者收到ACK报文段时将恢复计算时间为超时时间间隔;
- 这里的超时时间间隔的指数型增长,提供了一种简单形式的拥塞控制;
#### 快速重传
> TCP不使用否定确认 NAK
- TCP接收方发送ACK的动作
- 收到比期望序号要大的报文段,检测出现了间隔,则发送冗余ACK,也就是间隔低端的序号的确认号;
- 按序到达的报文段,等待下一个按序到达的报文段500ms,下一个没有在此时间间隔内到达,则发送ACK
- 单个积累ACK
- 接收数据间隔的报文段到达,发送ACK
- 接收方收到3个冗余ACK(快速重传的条件是3个冗余 ?为什么),TCP执行**快速重传**,即在该报文段定时器超时前重传丢失报文段;
- 选择确认,有选择的确认失序报文段,而不是累积到最后一个正确接收的有序报文段,与选择重传相结合;

### 3.5.5 流量控制
- TCP缓存溢出:TCP的两则都有接收缓存,TCP接收到正确的、按序的字节后,将数据放入缓存,应用程序从缓存中读取数据,如果应用当前其他事务繁忙,则有可能发送缓存溢出的情况;
- 流量控制服务(Flow-control service),匹配发送方的发送速率和接收方应用程序的读取速率;
- 流量控制
- RcvBuffer:配置的接收缓存的大小
- LastByteRead:从缓存中读取的数据的最后一个字节的编号
- LastByteRcvd:达到的按序报文段放入缓存的数据流的最后一个字节的编号
- LastByteRcvd - LastByteRead <= RcvBuffer 必须成立才可不发生溢出
- 当前的接收窗口:rwnd = RcvBuffer - [LastByteRcvd - LastByteRead]
- rwnd空间为动态变化的空间,rwnd值会被接收主机放入发给发送方的报文段的**”接收窗口“**字段,开始时rwnd = RcvBuffer
- 发送方跟踪的变量:LastByteSent, LastByteAcked
- 发送方在整个连接的生命周期内必须保证: LastByteSent - LastByteAcked <= rwnd
- 发送方要保证,当前所有未被确认的数据长度一定小于等于接收方返回的窗口长度
- 特殊情况:接收方窗口为0时,发送发将继续发送只有一个字节数据的报文段,接收方确认,当缓存清空后,确认报文将包含一个非0的窗口值rwnd;这里再清空前还是会发生重传;
- 注意:UDP不存在流量控制,所有对于UDP会出现缓存溢出
### TCP的连接管理
- TCP连接的建立与拆除
- 连接建立的过程会显著增加用户感受到的时延
- 网络攻击利用TCP连接管理的弱点、
#### 连接建立的步骤
> isn = identity sequence number
1. 第一步,**客户的TCP服务向服务端的TCP发送一个特殊的TCP报文段,该报文段不包含应用层数据,但是报文段的首部的标志位“SYN”的比特被置为1**;客户随机选择一个起始序号(client_isn),并将该编号放在TCP SYN报文段的序号字段中;**表示发起建立新的连接**
2. 第二步,包含TCP SYN报文段的IP数据报到达服务端,服务器从数据报中提取TCP SYN报文段,为TCP连接分配缓存和变量(这里分配的缓存和变量容易受到洪泛攻击),**并发送允许连接的报文段**,允许连接的报文段:不包含任何应用层数据,SYN标志位被置为1,确认号为client_isn+1,序号为随机选择的服务器初始序号 server_isn;**表示收到了发起连接的SYN的client_isn,同意建立连接,称作SYNACK报文段(SYNACK segment)**
3. 第三步,客户收到SYNACK报文段后,客户给该连接分配缓存和变量,**客户向服务端发送一个对服务端SYNACK的确认,确认序号为server_isn+1,且SYN被置为0,这个数据报中可以携带客户应用层数据;
- 这个步骤被称为“3次握手”,从第三个步骤开始次周的报文段传输的过程中SYN标志位都为0,建立的过程中交换了3个分组;
#### 连接拆除的步骤
> 两个进程都可以终止当前的连接,连接接收后,TCP服务分配的缓存和变量都会被释放和回收;
1. 客户应用程序发起关闭连接的命令,客户TCP向服务器发送报文段:首部标志位FIN被置为1;
2. 服务器收到FIN 为1的报文段后,向发送发会送一个确认报文段;
3. 服务器发送自己的终止报文段,其FIN比特被置为1;
4. 客户向服务端发送的终止报文段,发送一个确认,此时两台主机上用于该连接的所有资源都被释放;
#### 状态变迁
- **TCP状态 TCP state**
- 客户连接状态变化:
- CLOSED -> 客户向服务端发起一个连接,并发送SYN 1的无数据报文段
- SYN_SENT -> 接收到服务端会送的SYN 1的无数据报文段并且携带了对client_isn的确认,并发送对server_isn的确认 ,该确认只进行确认,SYN为0,且可以携带应用层数据
- ESTABLISHED -> 客户端连接建立成功; **拆除**: 应用层调用了关闭连接,TCP发送FIN标志位 1的报文段,客户进入等待FIN确认的状态
- FIN_WAIT_1 -> 接受到服务端回送的对FIN1的确认报文段,进入等待服务端发送FIN 1的报文段的状态;
- FIN_WAIT_2 -> 接收服务端回送的FIN 1的报文段,发送对该报文段的确认;
- TIME_WAIT -> 等待状态,等待30S后关闭连接,ACK丢失,TIME_WAIT状态使TCP客户重传最后的确认报文,TIME_WAIT消耗的时间与集体实现有关系,典型值30s,1min,2min
- CLOSED -> 连接关闭资源释放
- 服务端连接的状态变化:
- CLOSED -> 服务器创建一个监听套接字,进入LISTEN状态
- LISTEN -> 处于LISTEN状态的TCP服务,接收来自客户的SYN,并回送SYN和确认号+序号
- SYN_RCVD -> 进入已经接收SYN并等待ACK的状态
- ESTABLISHED -> 接收来自客户对SYN回报的确认正确接收ACK,ACK中包含服务端等待的的报文序号和服务端发送SYN的确认号,且可能包含数据,此时TCP服务将分配缓存及变量开始处理数据;
- CLOSE_WAIT -> **拆除**:处于已经建立了连接的服务端,收到一个FIN标志位为1数据报,并对客户发送收到确认,确认号及序号
- LAST_ACK -> 服务端主动向客户发送一个FIN标志位为1的的数据报
- CLOSED -> 接收来自客户对服务端发送的FIN数据报的ACK确认,不在发送数据,TCP和套接字 、进入关闭状态;
- 客户的TIME_WAIT作用,
- 1. 当主动关闭方处于TIME_WAIT状态时,一般会等待两个MSL(一般为60S),目的是确保,最后对被动方发送的FIN 1的报文的ACK确认报文段如果在网络中穿线丢失或者网络拥塞未到达处于LAST_ACK的被动关闭方,则被动关闭方可能会多次重传最后一个FIN 1的报文段,这样主动方可以发送ACK回复;
2. 如果做超时等待和重传,当该该端口和套接字再次建立新的TCP连接时,可能会导致新的连接收到被动关闭方最后的多次重传FIN 1的报文段的影响;所以TIME_WAIT时保障被动关闭方完全进入CLOSED状态,超时后主动发起方才会进入关闭状态并释放相应缓存和变量;
- 三次握手的最后一次,服务端等待客户发送最后的携带数据的ACK报文段,如果超时时间内没有收到(超时时间一般 为60s),则服务端将终止当前的半开连接,并回收资源;
- DoS攻击(Denial-of-service attack),SYN洪泛攻击(SYN flood attack),攻击者发送大量的TCP SYN报文段,不完成与server的三次握手,服务端不断对这样的半开连接分配资源(但资源未得到使用),导致服务器的连接资源被消耗殆尽;
- 防止攻击的手段时,使用SYN cookie,使用散列函数生成对SYN的特殊TCP序号,对返回的ACK报文段中的确认号和再次以相同方式计算散列函数的值相比较,也就是ACK=服务器返回的序号+1,这种情况下就可以判断是否要建立连接,否则对服务器无危害,因为服务器并没有分配任何资源,仅仅只使用了散列函数;
- 当TCP向一个不处于监听状态或者说不接收任何连接的端口,发送SYN建立连接的报文段时,接收主机的TCP将向源地址回送一个重置报文段,该报文段首部的RST标志位置为1;这个标志位表示的是**”我没有那个报文段的套接字,请不要再发送该报文段了“**;同样的问题出现再UDP套接字不匹配的情况时,接收主机将会发送一个特殊的ICMP数据报;
> nmap端口扫描工具
>
> 扫描一个TCP端口,发送一个TCP SYN 1的报文段,有可能的三种情况
>
> 1. 目的主机回送SYN ACK报文段,该端口的TCP连接处于打开状态(LISTEN)
> 2. 目的主机回送一个RST报文段,SYN报文段到达了目标主机,但是目标主机该端口未运行TCP应用
> 3. 源主机没有收到任何返回,标识SYN报文段被防火墙阻挡,无法到达目标主机
>
> nmap工具可以检查TCP打开的端口,打开的UDP端口,哈可以检查防火墙配置
### 3.6 TCP拥塞控制原理
- **异步传递方式 ATM**
- **可用比特率 ABR**
#### 3.6.1 拥塞原因和代价
- 两个发送方和一台具有无穷大缓存的路由器
- 两个主机各自有一条连接,且共享源和目的之间的单跳路由,PAGE 175
- 代价1:当分组到达的速率接近链路容量时,分组经历了巨大的排队时延;
- 共享输出**链路的容量** R
- 代价2:发送方必须执行重传以补偿因为缓存益处导致的分组丢失
- 代价3:发送方再遇到网络时延较大的情况下,会重传分组,导致路由器会利用链路带宽来转发一个不需要的分组副本;
- 代价4:一个分组沿着一条路径被丢弃时,每个上游的路由器对该分组的转发都是在浪费传输容量;
#### 3.6.2 拥塞控制方法
- 端到端拥塞控制:TCP通过端到端的方法解决拥塞问题,IP层不会向端系统提供有关网络拥塞的反馈;TCP接收方通过三次冗余确认告知接收方报文段的丢失,报文段的丢失就是一种网络拥塞的迹象,TCP会**相应的减小窗口长度**,往返的时延值作为网络拥塞程度的指示;
- 网络辅助的拥塞控制,网络层的路由器会向发送方提供关于链路中的拥塞情况;反馈方式为,阻塞分组(choke packet),路由器标记或更新从发送方流向接收方的分组中的某个字段来指示拥塞的产生;收到标记的分组后,接收方就会向发送方通知网络的拥塞;
#### 3.6.3 网络辅助的拥塞控制的例子:ATM ABR 拥塞控制
- ATM ABR拥塞控制算法,采用网络辅助的方法解决拥塞控制的协议;
##### ATM
- ATM采用面向虚电路(VC)的方法来处理分组交换;交换机将维护有关源到目的的VC状态;逐个VC的状态允许交换机跟踪各个发送方的行为,并采取相应的拥塞控制动作;例如跟踪分组的平均速率,显示的通知发送方减少发送分组的速率;
- ABR是一种弹性数据传输服务,ABR服务会在网络轻载时充分利用空闲的可用带宽;网络拥塞时,ABR服务会将其传输速率抑制为某些预先确定的最小传输速率;
> 详细:PAGE 180
### 3.7 TCP 拥塞控制
- TCP使用端到端的拥塞控制机制,IP层不向端系统显示的提供任何网络拥塞程度的反馈;
- 采用的方法:让每个发送方根据所感知的到的网络的拥塞程度来限制向连接发送流量的速率,动态调整流量发送速率,无拥塞时增加速率,有拥塞时降低速率;
- 拥塞控制的实现:
- 流量速率限制:TCP连接维护一个发送缓存,和一个接收缓存,和多个变量(接收方LastByteRead,LastByteRcvd,RcvBuffer,rwnd 发送方:LastByteSent,LastByteAcked);发送方会跟踪变量
”拥塞窗口“(congestion window)
,表示为
cwnd
;
- LastByteSent - LastByteAcked <= min { cwnd, rwnd}
- 发送方中**未被确认**的数据量不会超过 接收窗口和拥塞窗口中的最小值;
- 通过调节cwnd的值,发送方能够调整它向连接发送数据的速率;
- 感知拥塞:分组丢失后接收方发送3个冗余ACK,或者接收方出现超时,这时发送方就认为路径上出现了拥塞;
- TCP使用确认(或者计时)来触发增大拥塞窗口的长度,self-clocking;
- 一个丢失的报文段意味着拥塞,因此当丢失报文段时应该降低TCP的发送方的速率;
- 一个确认报文段指示网络在向接收方交付发送方的报文,因此,当先前未确认的报文段的确认达到时,能够增加发送方的速率;
- 带宽探测;增加传输速率以响应到达的ACK确认报文段,除非出现丢包事件,此时才减小传输速率;TCP发送方增加发送速率,到出现拥塞,从该速率后退,进而再次进行探测,检查拥塞是否发生了变化;ACK和丢包事件充当了隐式的信号;
- TCP发送方根据异步于其他TCP发送方的”本地信息“行动;
- TCP拥塞控制算法(TCP congestion control algorithm)
- 慢启动
- 拥塞避免
- 快速恢复
##### 慢启动
- slow-start,发送方的起始cwnd值为一个MSS,起始发送速率为MSS/RTT,每当传输的报文段首次被确认接收ACK,cwnd就增加一个MSS,在这个过程中每一个RTT,cwnd的值就会翻番,起始阶段很慢,但是在整个慢启动阶段以指数增加;
- 慢启动对超时和丢包事件的处理,即发送拥塞时的处理,有两种方式,1是将cwnd设置为1重新开始慢启动过程,将ssthresh(慢启动阀门)设置为cwnd/2,当出现拥塞将ssthresh设置为拥塞窗口的一半;当cwnd的值等于ssthresh时,结束慢启动并且将TCP转移到**”拥塞避免模式“**;
- 当检测到3个冗余ACK,这时TCP执行一种快速重传并进入**快速恢复状态**;
> TCP分叉 PAGE 193
##### 拥塞避免
- 进入拥塞避免的TCP,cwnd的值大约是遇到拥塞时的一半,这时每个RTT的确认ACK只将cwnd的值增加1个MSS;例如当前窗口每次发送10个报文段,假设每个报文段都有自己的确认ACK,则每次收到一个ACK,拥塞窗口的长度就增加1/10MSS,当10个ACK都收到时,就增加了一个MSS;
- 出现超时:cwnd的值被设置为1个MSS,ssthresh被设置为cwnd/2,并进入慢启动状态;
- 出现冗余ACK事件:TCP将cwnd减半,加上三个ACK的3个MSS,进入快速恢复状态
##### 快速恢复
- 进入快速恢复后,对每个收到的冗余报文段的ACK,cwnd的值增加一个MSS,当丢失报文的一个ACK到达时,TCP再降低cwnd后进入拥塞避免状态;
- 出现超时,执行与拥塞避免相同的操作,进入慢启动状态;
- 出现丢包,cwnd的值设置为1个MSS,将ssthresh的值设置为cwnd的一半;

#### 全局回顾
> 当TCP通过3个冗余ACK感知到了丢包,TCP进行的拥塞控制是:每个RTT内cwnd线性增加1MSS,出现3个冗余ACK事件时cwnd减半;
- TCP拥塞控制:**加性增**,**乘性减** additive-increase, multiplicative-Decrease AIMD
- TCP线性的增加他的拥塞窗口的长度(线性增加发送速率),直到出现3个冗余ACK事件,然后以两个因子来减少拥塞窗口的长度,然后又开始线性增长,探测是否还有另外可用的带宽;
- Reno算法
#### 吞吐量的宏观描述
- PAGE187
- 一天连接的平均吞吐量`0.75 x w /RTT` ,这里的w表示当前拥塞窗口的长度;
#### 经高带宽路径的TCP
- PAGE187
#### 公平性
- UDP没有内置的拥塞控制,UDP上的应用需要好以恒定的速率将数据注入网络中,UDP连接在TCP的观点看来时不公平的,因为它不与其他的连接合作,也不会适时的调整传输速率,TCP的拥塞控制在面临拥塞增加时,会降低其传输速率,原则上UDP并不会这样做;UDP源可能会压制TCP流量;
- TCP应用建立的并行连接会导致网络中应用程序带宽分配的不公平;
### 3.8 本章总结
------
# 4. 网络层
- 交付方式
- 数据报模式
- 虚电路模式
- 网络层功能
- 转发 forwarding
- 路由选择 routing
- 网际协议IP IPv4, IPv6
- 网络地址转换NAT
- 数据报分段
- 因特网控制报文协议ICMP
- 路由选择算法:链路状态和距离矢量算法,等级制路由选择方法;RIP,OSPF,IS-IS,BGP
### 概述
- 路由器的主要作用是将数据报(data grama)从入链路转发到出链路,路由器具有截断的协议栈,即没有网络层以上的部分;路由器除了控制目的外,不运行网络层以上的协议;、
### 4.1.1 转发和路由选择
- **转发:**将分组从输入链路移动到适当的输出链路的过程
- **路由选择:**网络层需要决定分组从发送方到接收方所要采用的路径或者路由,计算这些路径的算法为**路由选择算法** routing algorithm;
> 类比驾驶:驾驶车辆通过路段可以看作转发,查看地图选择到达目的地的路径可以看作路由选择;
- 每台路由器有一张
转发表(forwarding table)
;
- 转发表存储:分组首部的值和路由表的输出链路接口
- 路由器通过检查到达的分组首部的字段,用该字段值再转发表中查询,从而找出输出链路的接口
- 路由选择算法,决定了插入路由器的转发表中的值,路由选择算法可能是集中式的也可能是分布式的;
- 路由器接收路由选择协议报文,将报文信息用以配置路由转发表;
- 重要术语
- 分组交换机:一台通用分组交换设备,根据分组首部字段,从输入链路到输出链路来转移分组;
- 包括**链路层交换机** link-layer switches,基于链路层字段做转发决定;
- **路由器** router,基于网络层字段做转发决定;
- 连接建立 connection setup
### 4.2.1 网络服务模型
- 网络服务模型 network service model 定义了分组再发送与接收端系统之间端到端的端运输特性
- 网络层提供的服务
- 确保交付:确保分组最终到达目的地
- 具有时延上界的确保交付:确保分组交付,且再特定主机到主机时延上界内交付
- 有序分组交付:分组按照发送顺序达到目的地
- 确保最小带宽:主机以低于特定比特率的速率传输比特,则不会发送分组丢失,且分组再预定的时延内到达;
- 确保最大时延抖动:确保发送方两个相继分组间的时间量 = 目的地接收两个分组之间的时间量
- 安全性服务,使用源和目的主机知道的会话密钥,再源主机的网络层加密向目的主机发送的所有数据报负载;
- 因特网尽力而为服务(best-effort service),分组间的定时不能被保证,分组接受顺序也不能保证,发送分组最终是否能交付也不能保证;
- 恒定比特率(Constant bit rate,CBR) ATM网络服务;像发送方和接收方之间的一条专用的、固定带宽的传输链路;信元的端到端时延、时延抖动、丢失、推迟交付的比率都确保再特定值一下;
- 可用比特率(Available Bit Rate,ABR)ATM网络服务;最小信元传输速率(MCR)可以得到保证;网络有足够的空闲资源的情况下,发送方也会使用比MCR高的速率发送数据;
## 4.2 虚电路和数据报网络
- 网络层的面向连接服务和无连接服务
- 网络层的面向连接服务和无连接服务向运输层提供主机到主机的服务,运输层则是向应用层提供进程到进程之间的服务;
- 只在网络层提供连接服务的网络:**虚电路网络 Virtual-Circuit VC**
- 只在网络层提供无连接服务的网络:**数据报网络 datagram network**
- 运输层的连接服务只在网络边缘的端系统中实现,网络层的连接服务再端系统中和网络核心的路由器中实现;
- 计算机网路的两种基本类型:**虚电路网络, 数据报网络**
#### 虚电路网络
> 因特网时一个数据报网络
- ATM、帧中继的体系结构都是虚电路网络,在网络层使用连接,成为虚电路;
- 虚电路的组成:
- 源和目的之间的路径,链路和路由器
- VC号,沿着该路径的每段链路的一个号码;
- 沿着路径的每台路由器中的转发表表项;
- 每台路路由器会为分组替换一个新的VC号,分组在每条链路上有不同的VC号,且再分组的首部携带;
- 路由器的转发表会管理入VC号字段和对应的出VC号字段;
- 创建虚电路对路由器新增转发项,终止一条虚电路,删除相应的转发表项;
- 路由器需要对进行中的连接 维持**连接状态信息**,分组跨越一个路由器就创建新连接,增加路由器的表项,每释放一个连接从表中删除表项;
- 虚电路的3个阶段
- 虚电路建立,运输层向网络层指定接收方地址,网络层决定一条分组通过的路径,网络层沿着路径向链路中的每一个路由器节点决定VC,在转发表中增加表项;
- 数据传输,分组沿着创建号的虚电路流动;
- 虚电路拆除,发送方或者接收方通知网络层希望终止该电路时,网络层会通知另一侧的端系统结束呼叫并更新路径上的每台路由器的转发表;
- 沿着两个端系统之间的路径上的路由器都要参与虚电路的建立,且**每台路由器都完全知道通过它的所有虚电路**;
- 端系统向网络发送的指示网络层终止虚电路的报文,和路由器之间用来传递修改路由表的虚电路建立报文,位**信令报文** (signaling message),用来交换这些报文的协议位**信令协议** (signaling protocol);
#### 数据报网络
- 端系统为想要发送的分组加上目的端系统的地址,然后将分组推进网络中;路由器不维护任何虚电路;
- 分组在链路中经过每一台路由器,**路由器都是用分组目的地址来对分组进行转发**;
- 每台路由器维护一个**链路接口转发表**用来给目的地址做映射,对于到达分组,路由器会使用其首部的目的地址在链路转发表中查找适当的输出链路接口;然后路由器将分组向该接口转发;
- IPv4地址长度 32 位bit,4段(4 group)
- IPv6地址长度128位bit,8段(16进制,8group)
- 转发表:路由器用分组的目的地址的**前缀(prefix)**与该表中的表项进行匹配;当初先多匹配时,例如一个分组的目的地址与转发表中的21位表项匹配且又与24位表项匹配,**则路由器使用最长前缀匹配规则**,将该分组转发到24位表项相匹配的输出链路接口上,路由器总是在**链路接口转发表中**匹配最长的prefix,最长匹配项;最长匹配与编址规则有关;
- 路由器维护的转发表,维持了转发转台信息,转发表由**路由选择算法进行更新和修改**,路由器建立新连接和拆除一条连接都会更新转发表;
## 4.3 路由器的工作原理
> 回顾:链路层交换机实现第一层和第二层,路由器实现第一层到第三层,路由器能够实现IP协议,链路交换机不能,链路层交换机能够实现第二层地址,以太网地址
- **转发功能 (forwarding function)**
- 路由器的体系结构

- 输入端口:
- 物理层功能:将一条输入链路与路由器相连接
- 数据链路层功能:与位于入链路远端的数据链路层交互
- 通过查询转发表决定输出端口,到达分组通过路由器的交换结构转发到输出端口;
- 将“控制分组”从输入端口转发到路由器的“选择处理器”,(携带路由选择控制协议的分组)
> **端口**,这个词语在网络硬件中表示,路由器物理的输入和输出接口;
- 交换结构:
- 与输入端口和输出端口相连,交换结构完全包换在路由器中,网络路由器中的网络;
- 输出端口:
- 存储从交换结构接收的分组
- 执行相应的物理层和链路层功能,在输出链路上传输分组
- 双向链路,输出端口和输入端口在同一线路卡上成对出现;
- 路由选择处理器:
- 执行路由选择协议
- 维护路由表及连接的链路状态信息
- 计算转发表
- 执行网络管理功能
- **路由转发平面 router forwarding plane** :路由转发是路由器用输入输出端口、交换结构共同实现的转发功能,总是用“硬件”实现;
- 路由器对n个端口数据的处理,数据处理流水线需要n倍的处理速率,通过厂商定制的硬件来实现这样的功能;
- **路由器控制平面 router control plane** :通过软件实现,路由器的控制功能,包括执行路由选择协议,对上线和下线的连接链路进行响应,及路由的管理功能;
- 路由器和交换机的设计面对一系列的拥堵问题;
### 4.3.1 输入端口
- 输入端口的**线路端接功能** 与 **链路层处理** 实现了用于各个输入链路的物理层和链路层,执行输出链路处理,包括链路协议,和分组的拆封;
- 输入端口中:路由器使用转发表来查找输出端口,使得到达的分组能够经过交换结构转发到该输出端口;
- 转发表由路由器的选择处理器计算和更新,转发表的一份影子副本通常会被存放在每个输入端口;
- 转发表从路由选择处理器经过独立总线,复制到线路卡;
- 影子副本的作用:在每个端口本地作出转发决策,无需调用中央路由选择处理器,避免了集中式处理的瓶颈;
- 对于Gbps的链路,要求对转发表的查询必须在纳秒级别完成;
- 硬件执行查找
- 快速查找算法,快速搜索算法使用二分的思想,平均时间复杂度为logn,对于n为百万的情况,只需要执行20次
- DRAM和更快的SRAM的嵌入式芯片设计
- 三态内容可寻址寄存器(Tenary Content Address Memory, TCRM),该寄存器可以在常数时间内对地址的转发表项内容做返回
- 因为交换结构可能会被其他的分组使用,当前已经匹配了转发表项的输入分组需要在输入端口排队,并等待 被调度通过交换结构;
- 物理层和链路层处理
- 检查分组版本号、检验和、寿命字段,重写字段
- 更新用于网络管理的计数器(例如IP数据报的数目)
\> 对于路由器的输入端口,查找转发表然后进入交换结构进行转发,的过程可以抽象为“匹配加动作”,这个抽象在链路层交换机和防火墙中都存在;
### 4.3.2 交换结构
#### 三种交换技术
> 内存,总线,纵横
- 经内存交换
- 传统计算机的设计方式,CPU对分组进行在内存的I/O操作;
- 现代内存交换:输入线路卡查找转发表,并将分组放入适当的内存存储位置,也就是输出端口的内存
- 经总线交换
- 通过共享总线将分组发送到输出端口
- 输入端口为分组预先计划一个内部标签(首部),该标签用来标识输出端口
- 分组在总线上传送到输出端口
- 所有输出端口都会收到分组,只有与标签匹配的端口才将分组保存,然后标签在输出端口被去除
- 一次只有一个分组可以跨越总线,路由器的交换带宽受到其总线速率的限制;
- 经互谅网络交换
- 纵横式交换机是一种由2N条总线组成的互联网络;
- 连接N个输入端口和N个输出端口
- 垂直总线在交叉点和水平总线交叉,交叉点通过交换结构控制器能在任何时候开启和闭合;
- 对于来自不同输入需要达到不同输出端口的分组,纵横网络能够转发多个这样的分组;
- 对于进入相同总线的分组,还是需要排队等待;
### 4.3.3 输出端口
- 输出端口:取出存放在输出端口内存中的分组,并将其发送到输出链路上;
- 选择和取出排队分组进行传输,执行链路层和物理层传输功能;
### 4.3.4 排队
- 输入和输出端口处都会形成分组排队
- 排队位置和程度:取决于流量负载、交换结构的相对速率、线路速率;
- 随着队列增长,路由器的缓存空间最终耗尽,新到达的分组将会出现**丢包** packet loss;
- PAGE 218 描述了从理论到实践路由器转发分组的排队情况和路由器缓存配置情况
#### 分组调度程序 packet scheduler
- 服务原则
- 先来先服务 FCFS
- 加权公平排队 WFQ,端到端之间公平的共享输出链路
- 服务质量保证 quality-of-service guarantee
#### 丢弃到达分组的策略
- 弃尾策略
- 主动队列管理 Active Queue Management AQM 算法,在缓存满前就丢弃分组的策略
- 随机早期检测算法 广泛应用的AQM算法
- 算法思想:为输出队列长度维护一个加权平均值,平均队列长度小于阈值MINth,接纳分组,如果平均长度大于MAXth,则丢弃新到达的分组,如果平均长度处于[MINth MAXth],则使用函数概率标记或丢弃函数;
- 线路前部阻塞,一个输入队列中的排队分组,必须等待通过交换结构发送,即使当前目标的输出端口是空闲的,因为它被位于线路前部的另一个分组所阻塞;
### 4.3.5 路由选择控制平面
路由选择控制平面驻留并运行在路由器选择的处理器上,网络范围的路由选择控制平面是分布式的,不同功能部分执行在不同的路由器上,并且通过彼此发送控制报文进行交互;
## 4.4 网际协议: 转发和编址
- 编址和转发
- IPv4 IPv6
- 网络层的三个组件
- IP协议
- 路由选择,决定数据报从源地址到目的地址流经的路径
- ICMP协议:报告数据报中的差错,对网络层信息请求进行响应的设施
- 视图
| 运输层 TCP、UDP |
| :---------------------------------------------: |
| 路由选择协议 * 路径选择 *RIP OSPF BGP —> 转发表 |
| IP协议 * 编址规则 * 数据报格式 * 分组处理规则 |
| ICMP协议 * 差错报告 * 路由器 ”信令“ |
| 链路层 |
| 物理层 |
### 4.4.1 数据报格式
- 网络层的分组: **数据报** datagram
- IPv4 数据报格式
| IPv4数据报格式 32bit |
| :------------------------------------------------: |
| 版本 \| 首部长度 \| 服务类型 \| 数据报长度(字节) |
| 16比特标识 \| 标志 \| 13比特片偏移 |
| 寿命 \| 上层协议 \| 首部检验和 |
| 32比特源IP地址 |
| 32比特目的IP地址 |
| 选项(如果有的话) |
| 数据 |
- 版本:4个比特,IP协议版本
- 首部长度:4个比特,用来确定数据部分从哪里开始,不包含选项的情况,数据报首部为20字节
- 服务类型:TOS,实时数据报,非实时数据报,用来确定数据报的优先级
- 数据报长度:包括首部的IP数据报的总长度,16比特,最大理论长度2^ 16,65535
- 标识、标志、片偏移:IP分片
- 寿命:Time-To-Live TTL,每经过一个路由器,该值减1,TTl为0时丢弃,取保数据报不会永远在路由选择环路中循环转发;
- 协议:上层协议,6为TCP,17为UDP
\> 协议号:网络层与运输层绑定到一起的粘合剂 > > 端口号:运输层与应用层绑定到一起的粘合剂 > > 链路层帧
- 首部检验和:checksum,检验收到的ip数据报中的比特错误;
- 只对首部做检验
- 计算方式:将首部中的每2个字节,也就是16个比特相加在进行反码运算;
- 每个路由器都要对每个收到的IP数据报进行首部检验和的计算,检测出差错就丢弃,因为TTL每次都会减1,所有路由器会每次重新计算检验和并放置到数据报的检验和位置
- IP协议和TCP/UDP协议都需要进行检验和
1. IP数据报只是对数据报的首部进行检验
2. TCP/UDP是对整个报文段进行检验,而且报文段就是IP数据报的数据部分
3. TCP原则上可以运行在其他协议上 如ATM
- 源和目的IP地址
- 选项:允许IP首部被扩展,很少使用,已经在IPv6中去除
- 数据:有效载荷,运输层报文段,或者ICMP报文
> 对于无 “选项” 的IP数据报首部总长度为20个字节;
>
> 如果IP数据报承载了TCP报文段,则数据报承载了20字节的IP数据报首部,20字节的运输层TCP报文段的首部,及应用层报文;
#### IP数据报分片
- 对于不同的链路层协议,其能承载的网路层数据报的长度不同,以太网协议能承载1500字节的数据,某些广域网链路帧可承受不超过576字节的数据;
- **“最大传送单元”**:Maximum Transmission Unit, MTU, 一个链路层数据帧能够承载的最大数据量;
- 发送方和接收方的路径上的每段链路可能使用不同的链路层协议,每种协议都可能由不同的MTU;
- 对于过大的IP数据报,超过链路MTU的情况下,需要对IP数据报做分片;单独的链路帧将封装这些较小的IP数据报;然后将链路帧发送到链路上,每个较小的数据报为**“片”** fragment
- 分片方法:
- 发送端该数据报设置源目的地址的同时,会贴上“标识”,为每个发送的数据报标识加1;
- 路由器需要对数据报分片时,每个数据报都会由源目的地址和自己的标识号;
- 目的主机通过标识号确定那些数据报(片)是同一个大的数据报;
- 最后一片的标志比特为0,其他片的标志比特为1,目的是让目的端确定已经收到了所有的片;
- 偏移字段用来指定该片在数据报中的位置,目的端按照顺序组装,同时也可以确定数据报是否有片丢失;
- 目的端,只有当IP层已经完成了重构初始IP数据报时,有效载荷才会被传递给运输层;如果一片或者多片没有到达目的地,则不完整的数据报会被丢弃,不会交给运输层;TCP超时重传、选择重传、快速重传
- Jolt2 DoS攻击
### 4.4.2 IPv4 编址
- 主机与路由器连入网络
- 一台主机通常只有一条链路连接到网络;
- 主机和物理链路之间的边界叫做**接口 interface**;
- 一个ip地址与一个接口相关联,不与主机及路由器相关联;
- IP地址,32bit,点分十进制法书写;
- 因特网处NAT之外的每台主机的接口都有一个唯一的IP地址;
- IP地址的一部分由连接的子网来决定;
- 例子:
- 3台主机与1台路由器相连,4个接口的ip地址的前24bit相同;
- 3个主机的接口与一个路由器的接口形成一个子网(subnet);
- IP编址为这个子网分配一个地址,**”/24“**,为子网掩码(network mask),这表示32bit中最左侧的24比特定义了子网地址;
- 任何需要连入该子网的主机,ip地址都需要具有与前24bit子网地址相同的形式;
- 确定网络中子网的方法:
- 分开主机和路由器的每个接口,产生几个隔离的网络岛,使用接口“端接”隔离的网络端点,隔离的网络中的每一个都是一个子网(subnet)
- 一个具有“多个以太网段”和点对点链路的组织将具有多个子网;
- 地址分配策略:
- 无类别域间路由选择(Classless Interdomain Routing,CIDR)
- CIDR将子网地址划分为两部分,表示为a.b.c.d/x,其中x表示地址的第一部分的比特数;
- a.b.c.d/x 的地址的x 最高比特构成了ip地址的网络部分,地址的前缀(prefix)(网络前缀);
- 路由选择协议,转发只考虑该网络前面的前缀比特x,这就减少了路由器中转发表的长度;
- 实践原则:
- 地址聚合 address aggregation:使用单个网络前缀通告多个网络或多个子网的能力
- 也称作 路由聚合 route aggregation,路由摘要 route summarization
- 一个地址剩余的32-x比特用来区分内部设备;只有内部设备连接的内部路由器在转发分组时,才会考虑这些剩余的bit;低级的bit可能有另外的子网结构;
- 例如:a.b.c.d/21中的前21个比特表示当前组织的网络前缀,a.b.c.d/24表示组织内部的子网;
- 分类编址,旧方式
- ip广播地址 255.255.255.255,当一台主机向广播目的地址发送数据报时,该报文会交付给同一子网内所有的主机;
- 获取地址
- 从ISP获取,因特网名字和编号分配机构获取;(Internet Corporation for Assigned Names and Numbers,ICANN)
- DHCP 动态主机配置协议
- DHCP允许主机自动获取(被分配)IP地址,可以配置,在每次连接外部网络时都能获得相同的IP地址,或者被分配一个**临时的IP地址**(temporary IP address);
- DHCP还允许主机得知,子网掩码,第一跳路由器地址(默认网关),与本地DNS服务器地址
- DHCP为 **即插即用协议** plug-and-play protocol
- DHCP在主机加入或者 离开网络时,DHCP服务器会更新可用IP地址表;一台机器加入,则从当前可用地址池中分配任意一个地址;主机离开时,地址会回收到该地址池中;
- 客户-服务器协议,客户为新到达的主机,客户需要获取一个自身使用的IP地址和网络配置信息;如果该网络中没有DHCP服务器,则需要一个DHCP中继代理;
- 对于新到达的主机DHCP的四个步骤:
1. DHCP服务器发现,DHCP发现报文(DHCP discover message),客户使用UDP的DHCP发现报文,以广播地址255.255.255.255作为目的地址,本机源地址0.0.0.0作为源地址,67作为目标端口,DHCP客户将IP数据报传递给链路层,链路层将帧广播到所有与该子网连接的子网;
2. DHCP服务器提供,DHCP服务器收到报文后,用DHCP提供报文(DHCP offer message)向客户做出响应;仍然使用广播地址
1. 提供报文包括:发现报文的事务ID,向客户推荐的IP地址、网络掩码及IP地址租用期(address lease time)
3. DHCP请求,客户从多个DHCP服务器中选择一个,并向服务器发送DHCP请求响应(DHCP request message)进行响应,回显配置参数;
4. DHCP ACK,服务器用DHCP ACK报文对DHCP请求报文进行确认响应;
- 客户收到DHCP ACK之后,交互完成,客户可用在租用期之内使用分配的IP地址,如果超时后还希望继续使用,DHCP提供一种机制允许用户更新对地址的租用;
- 网络地址转换 NAT Network Address Translation
- NAT**“使能”**路由器对于外部网络来说,就是一台具有单一ip的设备,所有离开这个NAT子网的数据报,都有同一个源地址IP,所有进入该网络的数据报都有同一个相同的目的IP;
- 本质:NAT使能路由器对外界隐藏了内部网络的细节;
- 在此网络内部,有独立的NAT-DHCP服务为内部的设备分配IP,路由器从ISP的DHCP服务获取外部IP;
- **NAT转发表** NAT traslation table
- 表中包含了WAN端的IP地址和端口 及 映射的 LAN端 IP地址和端口
- 对于本地子网要发送的数据报,NAT会将内部子网主机的IP地址及端口号,记录在转发表的LAN端,NAT路由器收到数据报后会生成一个新的源端口(选择当前任意一个不在转换表中的端口,支持超过60 000个并行的广域网IP地址连接),并将**数据报中的端口改为新的源端口,IP地址改为NAT的接口的广域网IP地址,并将数据报发送到目的地址;目的主机无法感知数据报中的源IP和端口都经过NAT协议的改装;
- 目的端响应报文到达NAT路由器时,路由器会使用数据报中的源IP地址和源端口检索出内部子网主机的ip和端口,并改写数据报的目的IP和目的端口,并向主机转发该数据报;
> 主机通过DHCP服务器,获取了第一跳路由器的地址(网关),和自己的IP地址、子网掩码、DNS域名解析服务器的IP地址,主机会将包含目的IP和端口号的数据报直接发送到第一跳路由器(中间可能会经过NAT服务,例如家庭路由器上运行的NAT服务),路由器会对分组进行转发;
- NAT对P2P应用的影响:连接反转,NAT穿越
- UPnP,即插即用协议,plug-and-play-protocol
- UPnP允许外部之际使用TCP或UDP向NAT化的主机发展期通信会话;UPnP提供了有效的NAT穿越解决方案;
- UPnP协议的主要作用是:允许主机发现并配置NAT协议
- 使用UPnP,在主机上运行的应用程序能够为某些请求的公共端口号,请求一个NAT映射;UPnP让应用程序知道公共IP和公共端口,应用程序就可以将该公共IP和公共端口通知到目的主机,目的主机通过公共IP和公共端口与源主机通信;
### 4.4.3 因特网控制报文协议 ICMP
- **ICMP协议 Internet Control Message Protocol**,用于主机和路由器之间彼此沟通网络层信息,如差错报告;
- 例如在通常的应用层协议中收到的“目的网络不可达”的错误报文,就是由ICMP产生的;
- 当路由器无法找到一条路径通向目的地址时,该路由器就会向源主机发出类型3的ICMP报文;
- ICMP为IP的一部分,但是在体系机构上位于IP协议之上;ICMP报文段承载在IP数据报中;ICMP报文也时IP有效载荷;
- 主机收了指明了上层协议为ICMP的IP数据报时,解析出来的数据报内容会发送到ICMP服务;
- ICMP报文字段包括:
- 类型字段
- 编码字段
- 引起ICMP报文生成的IP数据报的首部和前8个字节的内容;用于发送方确定出错的数据报
- ICMP类型 编码 描述
- 4 0 源抑制 拥塞控制 这里的拥塞控制的方式:路由器向主机发送一个ICMP源抑制报文,强制主机减小其发送速率,TCP有自己的拥塞控制机制;

- ping程序基于ICMP的工作原理
- ping程序发送一个 **ICMP** 类型8编码0的报文到指定主机
- 目的主机收到回显echo请求,目的主机返回一个**类型0,编号0** 的ICMP回显回答;
- linux操作系统支持ping服务器,该服务不是一个进程([源代码](https://github.com/torvalds/linux/blob/master/net/ipv4/ping.c))
- IP协议规则:路由器丢弃一个数据报并发送一个ICMP告警报文给源主机,告警报文包含路哟求名称和IP地址;
- Traceroute使用特定TTL值的UDP报文来探测源和目的之间的路由器的数量和标识,以及两台主机之间的时延,对于到达目的主机的UDP报文段,由于端口不可达,所有目的主机会返回一个ICMP报文;
> 防火墙和入侵检测系统(IDS),关注安全性PAGE238
>
> 防火墙可用阻挡ICMP回显请求分组,从而防止ping检测
>
> 防火墙也可以基于IP地址和端口号配置特殊的过滤策略
>
> IDS位于网络边界,执行**“深度分组检查”**,检查数据报的首部,检查有效载荷;并分享分组特征数据库
### 4.4.4 IPv6
- IPv6数据报格式
| 32bit |
| :----------------------------------: |
| 版本 \| 流量类型 \| 流标签 |
| 有效载荷长度 \| 下一个首部 \| 跳限制 |
| 源地址 (128bit) |
| 目的地址 (128bit) |
| 数据 |
- IPv6数据报格式变化
- 扩大的地址容量
- 地址容量从32bit扩大到128比特,用16进制表示;
- IPv6引入了**任播地址** (anycast address),用来将数据报交付给一组主机中的任意一个;
- 简化的高效的40字节首部
- 40字节定长首部,去除IPv4中的选项字段,允许更快的处理IP数据报
- 流标签与优先级
- Flow:给属于特殊流的分组加上标签,这些特殊流是发送方要求进行特殊处理的流,如一种非默认服务质量或需要实时服务的流;
- 音频和视频的传输就是一种“流”
- 流量类型字段,类似与IPv4中的TOS字段,用于给出一个流中某些数据报的优先级,用来指示某些应用程序的数据报比其他应用有更高的优先权;
- IPv6数据报的结构更简单,更高效:
- 版本:4bit,用于标识IP版本号; 6
- 流量类型:8bit,与IPv4中的TOS字段含义相似
- 流标签:20bit,用于标识一条数据报的流
- 有效载荷长度:16bit,给出IPv6数据报中定长40字节的首部后面的数据部分的比特数;
- 下一个首部:标识数据报中的内容需要交付给,哪个协议(TCP/UDP)与IPv4中的上层协议字段相同
- 跳限制:转发数据报的每台路由器对该值减1,当计数为0时,数据报被丢弃;用来限制数据报转发的路由器数量,防止数据报在环路中一直存在;
- 源地址和目的地址:128bit的源地址和目的地址字段
- 数据:有效载荷部分,包括运输层报文段的首部及应用层数据部分
- IPv4数据报中的字段在IPv6中已不存在
- 分片/重新组装:IPv6不允许路由器对数据报进行分片和组装;分片和重新组装只在源和目的端执行;当路由器遇到较大分组无法转发到链路时(如超过1500个字节),直接将数据报丢弃,并向发送方回复“分组太大的” ICMP差错报文,ICMP报文也封装在IP数据报中;这样发送端收到ICMP报文后,将数据报在端系统出进行分片,从而加快了转发速率;
- 首部检验和:为了快速处理IP分组,将检验和去除,数据报中只有运输层报文端有首部检验和做检验;(IPv4的耗时主要体现在每个数据报都有自己的TTL,所有每个路由器进行检验后,还需要更新数据报中的检验和)
- 选项:选项字段去除,但是任然有选项的存在,如“下一个首部”字段指向的位置有可能时“选项”
- IPv4到IPv6的迁移
- **双栈**, 有发送和接收IPv4,IPv6两种数据报的能力;
- IPv6/IPv4节点必须有IPv6和IPv4两种地址;
- IPv6数据报可以转换成IPv4数据报,但是会丢失IPv6数据报首部 一些在IPv4中无对应项的字段信息;
- 建隧道(tunneling),两个端系统进行IPv6数据报的交换,但是中间有一个IPv4的路由器,两个IPv6路由器之间的IPv4路由器的集合为 **隧道** Tunnel,借助隧道,在隧道发送端的IPv6结点,将IPv6数据报方到一个IPv4数据报的数据部分(有效载荷),该IPv4数据报通过中间路由被转发到隧道接收端,隧道接收到取出IPv6的数据,然后再为IPv6的数据报提供转发;
### 4.4.5 IP安全性
- IPsec 和 密码学基础
- IPsec兼容IPv4,IPv6
- IPsec只在端系统中可用,运输模式
- 两个端系统先创建一个IPsec会话,IPsec是面向连接的
- 发送端运输层向IPsec传递一个报文段,IPsec加密该报文段,并在报文段上附加安全性字段,再封装到IP数据报中;
- 目的主机,IPsec将解密报文段并将脱密的报文段发送给运输层;
- IPsec会话提供的服务包括:
- 密码技术约定;两台主机之间的加密算法和密钥保持一致
- IP数据报有效载荷加密;
- 数据完整性,IPsec允许主机验证数据报的首部,保证被加密的有效载荷在传输过程中没有被修改过
- 初始鉴别,受信任的源收到IPsec数据报,确信数据报中的源IP是该数据报的实际源
- 两台主机之间创建了IPsec会话,两主机之间的所有TCP和UDP的报文段都将会被加密和鉴别;
## 4.5 路由选择算法
- 主机通常直接和一台路由器相连
- 该路由器为该主机的 **默认路由器 default router**
- **第一跳路由器 first-hop router**
- 源主机的默认路由器为:**源路由器(source router)**
- 目的主机的默认路由器为**目的路由器 destination router**
- 路由选择: 源路由器到目的路由器的路由选择
> | 源主机 —> (默认路由器 | 第一跳路由器 | 默认网关 | 源路由器) —> {中间链路及路由器} —> 目的路由器 —> 目的主机 |
> | --------------------- | ------------ | -------- | --------------------------------------------------------- |
> | | | | |
- 路由选择算法的目的:
- 给定一组路由器及连接路由器的链路,路由选择算法就是要找到一条从源路由器到目的路由器的**“好”**路径;
- 简单的网络结构抽象可以用“图”graph(无向图)的数据结构来表示,G=(N,E),N表示图中的每个顶点的集合,E表示每条弧也就是每个路由器之间的链路的集合;每条弧上的权值代表这条链路的费用(费用反应出了一条边的物理链路的长度、速度、金融费用);
- 属于E的一条弧的顶点 (x, y) ,y也被称为x的邻居(neighbor);
- 路由选择算法的目标是找到**最低费用路径**
- 源路由器和目的路由器之间最少链路数量为**最短路径**;
- 当一个位置或结点有该网络的完整信息,再该节点的路由选择算法就是“集中式的”
- 分类
- 全局式的路由选择算法(global routing algorithm)
- 该算法为“集中式的全局路由选择算法”
- 输入为所有节点的连通性及链路的费用,算法执行前需要获取全局的完整信息;
- 全局状态信息:**链路状态算法**
- 分散式路由选择算法(decentralized routing algorithm)
- 以迭代、分布式的方式计算出最低费用路径,迭代的每个节点逐渐的计算到达某目的节点的最低费用;
- 距离向量算法(Distance-Vector, DV)
- 第二种广义分类
- 静态路由选择算法(static routing algorithm),路由变化缓慢,通常人工调整
- 动态路由选择算法(dynamic routing algorithm),网络流量负载或者拓扑发生变化时改变路由选择路径;动态算法周期性的运行或者对拓扑变化直接响应
- 第三种分类
- 负载敏感算法(load-sensitive algorithm)
- 负载迟钝算法(load-insensitive algorithm),链路费用无法直接反应链路拥塞水平
### 4.5.1 链路状态路由选择算法 Link-State
- 链路状态算法中,网络拓扑和所以的链路状态都是已知的,并且作为LS算法的输入
- 实践中
- 让每个结点向网络中所有其他结点广播链路状态分组
- 每个链路状态分组包含它所连接的链路的特征和费用 例如OSPF路由选择协议
- 链路状态广播算法 (link state broadcast)来完成
- 广播的结果是该网络中的所有结点都具有了与该网络等同的、完整的视图
- 每个结点都能运行LS算法计算出最低费用的集合
- Dijkstra算法 - Prim算法 O(n^2)
- Dijkstra算法计算源结点到网络中其他所有结点最低费用路径
- 迭代算法,经过k次迭代后,可以直到k个目的结点的最低费用路径
- 算法思想:
- 保存每个结点的最低费用,和集合N’
- 每次迭代找出不属于N’且最小费用的节点,将它加入N’,并遍历它的所有邻居节点,并更新最小费用;
- 迭代次数为节点总数
- 算法步骤:
1. 将源节点加入集合N’中,获取和源节点相邻节点,最小费用为链路费用,如果不相邻最为正无穷
2. 找到上一次所有链路费用最小的点x,将x加入N‘,遍历x的所有邻居节点,并为这些节点更新其最小链路费用
- 通过对每个目的节点存放从源结点到目的结点的最低费用路径上的**”下一跳结点“**,结点中的转发表就能够根据此信息构建;
- 此算法的最差时间复杂都为 O(n^2),使用堆的数据结构,可以将时间复杂度降低到logn级别
- 当链路的费用依赖于当前链路所承载的流量时,链路状态选择算法会出现**”振荡“**,解决方式是确保路由器不同时运行LS算法;
### 4.5.2 距离向量路由选择算法
- **距离向量 (Distance-Vector)**算法
- 迭代:获取信息和执行计算的过程需要持续到邻居之间无更多的信息交换为止
- 异步:不要求所有结点步骤一致的进行操作
- 分布式:每个结点要从一个或者多个直接相邻的结点获取信息,执行计算,将结果分发给邻居
\> Bellman-Ford方程: > > dx (y) = min v { c(x, v) + d v (y) } > > 获取x到所有邻结点的费用,取从这些邻结点v到目标结点y的最小费用,则x到y的最小费用是所以邻居v的 **c(x, v) + d v (y)** 的最小值 > > 详见:Page 258
- **DV算法的基本思想**
- 每个结点x,对N中的所有结点,估计从自己到结点y的最低费用;
- 每个结点x,维护的信息如下:
- 对于每个邻居v,从x到直接邻居v的费用 c(x, v)
- 结点x的距离向量,包含了x到N中所有目的地y的费用估计值
- 每个邻居的距离向量,x的每个邻居v
- 算法思想的理解:
- 该算法以分布式的方式,在网络中,每个结点接收相邻结点的距离向量副本,每次更新都会触发结点向响铃结点广播自己最新的距离向量;
- 每个结点根据B-F方程的思想不断更新自己缓存的到其他每个结点的最小距离;(最低费用)
- 当所有结点触发的更新完成后,也就是不再有异步更新时,该网络中的路由选择表趋于稳定;
- [路由器](https://zh.wikipedia.org/wiki/路由器)需要周期性与相邻的路由器交换更新通告(routing updates),动态建立路由表,以决定最短路径。
- 伪代码:再该分布式、异步的算法中,每个结点不时的向它的每个邻居发送它的距离向量副本,当结点x从它的任意一个邻居v接收到新的距离向量,保持v的距离向量,然后使用Bellman-Ford方程更新他自己的距离向量,对每个节点;结点x的距离向量更新后,向每个邻居发送更新后的向量;最终结果会收敛到最低费用路径;
TODO : PAGE258
Dijkstra算法,LS算法是全局的,在运行之前需要先获取整改网络的完整信息
DV算法是分布式和异步的,每个结点具有的信息是他到直接相邻结点的链路费用,和它收到的这些邻居发给它的信息;
DV算法的实践: RIP、BGP、ISO IDRP、Novell IPX
- 从邻居接收更新的距离向量、重新计算路由选择表 和通知邻居到目的地的最低费用路径的费用已经发送变化,这个过程会持续下去,直到无更新报文发送为止;这时算法进入等待状态,直到再次有线路费用变化触发算法;
1. 距离向量算法:链路费用改变与链路故障
- 在链路费用变化的过程中,如果某个结点接受了邻居结点的信息后,路由选择表并没有更新,则该结点不再向其邻居结点发送信息;
- 路由选择环路 routing loop
- 分组将在两个结点之间不停的转发,例子见Page262
- 无穷级数问题 count-to-infinity
2. 距离向量算法:增加毒性逆转
- 毒性逆转 (poisoned reverse),可以避免路由环路
- 思想:例子PAGE 262
- 无法解决3个或者更多系欸但的环路问题
3. LS与DB路由选择算法的比较
DV和LS算法采用互补的方法来解决路由选择计算问题;
比较 N为结点集合(路由器) E是边(链路)集合
报文复杂性
LS算法要求每个结点都知道网络中每条链路的费用,要求发送O( N E )个报文;一条链路如果发生了改变,则需要向所有结点发送新报文; DV算法要求每次迭代时,在两个直接相邻的结点之间交换报文;当链路费用发生变化时,DV算法仅在新的链路费用,导致与该链路相连的结点的最低费用改变时,才会向其他相邻结点传播费用信息,如果不在发生改变则不会在向相邻结点发送;
收敛速度
LS算法实现的时一个O( N E )个报文的O(n^2)的时间复杂度 DV算法收敛较慢,而且遇到路由选择环路时,会遇到无穷计数的问题;
健壮性
- LS:一个结点可以会损坏或者丢弃它收到的LS广播分组,但是LS结点只计算自己的转发表,每个结点各自接收广播分组,各自进行计算,提供了一定程度的健壮性;
- DV算法:一个结点如果产生了错误的链路费用,会通知它所有的相邻结点,这个错误会一直扩散到整个网络的所有路由器上;
4. 其他路由选择算法
- 因特网实践中仅有的两种类型的算法:LS算法和DV算法
4.5.4 层次路由选择
实践和路由选择算法模型
- 规模,当前的因特网上路由器需要巨大容量的内存存储路由选择信息;路由器的LS广播的开销会导致没有剩余的带宽用来发送数据分组,大量路由器中算法将永远无法收敛;
- 管理自治,网络需要按照意愿进行管理,还需要和外部其他网络连接;
自治系统 Autonomous System AS
每个AS由一组通常处于相同管理控制下的路由器组成
相同的AS中的路由器全都运行的同样的路由选择算法(如一种LS或一种DV),且拥有彼此信息;
在一个自治系统内运的路由选择算法:自治系统内部路由选择协议 intra-autonomous system routing protocol
在AS内部有一台或者多台路由器 ”网关路由器 gateway router“,负责向本AS之外的目的地转发分组;
源AS只有一台网关路由器,且只有一条通向外部AS的链路时,分组会直接通过该链路传输;
自治系统之间的路由选择协议(inter-autonomous system routing protocol),AS间路由选择协议
BGP4
- 从AS间协议知道经过多个网关可达子网x
- 使用来自AS内部协议的路由选择信息,以决定到每个网关的 最低费用路径 的费用
- 热土豆路由选择(hot potato routing),选择具有最低费用的网关
- 从转发表确定通向最低费用网关的接口I,将(x,I)项田间道转发表中
4.6 因特网中的路由选择
一个AS是一个处于相同的管理与技术控制下的路由器集合,在AS之间都运行相同的路由选择协议;每个AS通常又都包含多个子网;
4.6.1 自治系统内部的路由选择:RIP
AS内部的路由选择方式,用于确定在AS内执行路由选择的方式
AS内路由选择协议,又称为:
内部网关协议 interior gateway protocol
,包括:
- 路由选择信息协议 Routing information Protocol RIP
- 开放最短路优先 Open Shortest Path First,OSPF
RIP Routing information Protocol RIP
最早使用的AS内部的路由选择协议,广泛应用
距离向量协议,运行方式类似DV
RIP中费用从源路由器到目的子网;
RIP使用 ”跳“,跳是沿着源路由器到目的子网的最短路径经过的子网数量;
一条路径的最大费用被限制为15,RIP的使用限制在网络直径不超过15跳的自治系统内;
DV协议:任何一台路由器的距离向量是从这台路由器到该AS中子网的最短路径距离的当前估计值;
路由器和相邻路由器的信息交换使用:RIP 响应报文 RIP response message 来交换,大约没30秒交换一i此;
由一台路由器发送的响应报文,包含该AS内多达25个目的子网列表,及发送方到每个子网的距离;
RIP响应报文:RIP通告 RIP advertisement
每台路由器维护一张“路由选择表 routing table“;
路由选择表包括
- 距离向量
- 转发表
- 第一列:目的子网
- 第二列:沿最短路径到目的子网的路由器标识
- 第三列:到达目的地的跳数
目的子网 下一台路由器 到达目的地的跳数 RIP每30秒相互交互一次,如果一台路由器180秒都没有从邻居收到报文,则认为邻居不再可达,RIP修改本地路由选择表,然后向其他邻居发送通告来传播该信息;
路由器也可以通过使用RIP报文,请求邻居到指定的目的地的费用;
路由器在UDP上使用端口520互相发送RIP请求与响应报文;
RIP使用一个位于网络层IP协议之上的运输层UDP协议来实现网络层的路由选择功能
- 工作原理
- RIP在路由器操作系统中,以routed名称的进程运行,来维护路由选择信息和相邻的路由器上的routed进程交换报文;
- 因为RIP的实现是一个应用层进程,所有它能在标准的套接字上发送和接收报文,并使用标准的运输层协议;
- RIP是一个运行在UDP上的应用层协议,但他实现的功能是网络层的功能;
- 工作原理
4.6.2 自治系统内部的路由选择: OSPF Open Shortest Path First,OSPF
OSPF通常设置在上层的ISP中,RIP被设置在下层ISP和企业网中;
OSPF的路由协议规范是公众可用的;
OSPF核心:
- 一个使用洪泛链路状态信息的链路状态协议
- 一个Dijkstra最低费用路径算法
- 使用OSPF,一台路由器构建了一副关于整个自治系统的完整拓扑图,路由器运行Dijkstra最短路径算法,以确定一个以自身 为根节点的到所有子网的最短路径数;
- OSPF提供机制,为“给定链路权值集合”确定最低费用路劲路由选择
原理
- OSPF,路由器向自治系统内所有其他路由器广播路由选择信息;
- 当一条链路发生变化,路由器就会广播链路状态信息,当链路状态未发生变化,路由器会周期性的广播链路状态信息(至少每30min)
- OSPF报文,由IP协议承载,上层协议值为89,OSPF协议自己实现可靠报文传输、链路状态广播等功能
- OSPF要检查链路正在运行,并允许OSPF路由器获得相邻路由器的网络范围链路状态的数据库
OSPF的优点
- 安全;能够鉴别OSPF路由器之间的交换;使用鉴别,只有受到信任的路由器能参与AS内的OSPF协议;MD5散列值计算;
- 多条相同费用的路径;出现多条相同费用路径时,OSPF允许使用多条路径;
- 对单播和多播路由选择的综合支持;多播:使用现有的OSPF链路数据,为现有的OSPF链路状态广播机制增加了新型的链路状态通告;
- 支持在单个路由选择域内的层次结构;具有按层次结构构建一个自治系统的能力
一个OSPF自治系统可用配置成多个区域,每个区域都运行自己的OSPF链路状态路由选择算法;
一个区域内每台路由器都向该区域其他所有路由器广播其链路状态
一个区域内,有一台或者多台区域边界路由器 area border router,负责为流向该区域以外的分组提供路由选择;
AS内只有一个OSPF区域配置成
主干(backbone)
区域;
- 主干区域的主要作用是,为AS内其他区域之间的流量提供路由选择;
- 主干包含:AS内的所有区域边界路由器,和一些非边界路由器
- 在AS内的区域间的路由选择要求,分组首先到达一个区域边界路由器,再通过主干路由器到位于目的区域的区域边界路由器,然后再到最终目的地;
实践原则:设置OSPF链路权值,PAGE270
4.6.3 自治系统间的路由选择:BGP
RIP 和 OSPF 来决定位于相同AS内部的源和目的之间的路由选择路径;
跨越多个AS的源和目的之间的路由选择,边界网络协议 Border Gateway Protocol, BGP
当今因特网中域间选择协议事实上的标准;BGP4或BGP
工作手段
- 从相邻AS处获得子网可达信息
- 向本AS内部的所有路由器传播这些可达信息
- 基于可达性信息和AS策略,决定到达子网的 “好” 路由
> BGP 使得每个子网向因特网的其余部分通告自己的存在; > > BGP保证在因特网中的所有AS直到该子网以及如何到达;
1. BGP基础
- 路由器通过使用”179“端口的半永久TCP连接,来交换”路由选择“信息;
- 半永久TCP连接:该连接位于两个不同AS的路由器的链路;
- 一个AS内部的路由器之间的BGP TCP连接:在AS内部形成网状TCP连接;
- 对于每条TCP连接,位于连接端点的两台路由器为“BGP对等放 BGP-peers”,沿着连接发送的BGP报文的TCP连接为BGP会话 BGP session,跨越两个AS的BGP会话为外部BGP会话 eBGP external BGP session,同一个AS中的会话为”内部BGP会话 iBGP internal BGP session”
实践原则:PAGE 272
- BGP使得每个AS直到经过其相邻AS可以到达那些目的地,BGP中,目的地不是主机而是Classless Inter-Domain Routing、CIDR化的前缀prefix,每个前缀代表一个子网或者一个子网的集合
- 任何AS中的网关路由器,接受到eBGP学习到的前缀后,该网关路由器使用它的iBGP会话来向该AS中的其他路由器发布这些前缀;
- 当路由器得知一个新前缀时,它为该前缀在其转发表中创建一个项;
2. 路径属性和BGP路由
BGP中,一个自治系统由其全局唯一的自治系统号 Autonomous system Number ASN所标识;例如桩 stubAS通常没有ASN,桩AS仅仅承载源地址或者目的地址为本AS的流量;
类似与IP地址,AS号由ICANN地区注册机构分配
路由器通过BGP会话通告一个前缀,前缀中包含BGP属性(BGP attribute),带有属性的前缀叫做 一条BGP路由 route,BGP对等方彼此通告路由;
属性 AS-PATH
- 包含来前缀通告已经通过的AS
- 当一个前缀传送到一个AS时,该AS将它的ASN怎加到AS-PATH属性中;
属性 NEXT-HOP
- 是一个开始某AS-PATH的路由器接口
- 路由器利用NEXT-HOP属性正确的配置他们的转发表
对于两条路由具有到前缀x的相同AS-PATH,但有不同的NEXT-HOP值对应于不同的对等链路;使用NEXT-HOP值的AS内部路由选择算法,路由器能够确定到每条对等链路的费用,使用热土豆路由选择来决定适当的接口;
WIKI: 热马铃薯路由选择(Hot-potato routing)是在当前AS接收到一个数据包后,使其停留在该AS中的时间尽可能短。在“热马铃薯路由”这个名字中,数据包被类比成了你手中的一个滚烫的马铃薯,因为它很烫,所以你想要尽可能快地把它传递给另一个人(另一个AS)
其他属性
允许路由器对路由分配偏好测度的属性
指示前缀如何插入位于起始AS的BGP属性
当一台网关路由器接收到一台路由器的通告时,它使用其
输入策略(import policy)
来决定是否接收或者过滤该路由,是否设置某种属性;
- 输入策略可能会过滤一条路由,因为AS可能不希望通过该路由AS-PATH中的某个AS来发送流量;
- 网关路由器也可能过滤一条路由,因为已经知道了一条相同前缀的偏好路由
3. BGP路由选择
BGP使用eBGP和外部建立会话,向外部路由器发布路由
BGP使用iBGP和内部路由器建立会话,向内部路由器发布路由
路由:带有BGP属性的ip前缀
对于BGP发布的路由,路由器可能到达任何一条前缀的多条路由,路由器进入路由选择进程,输入为路由器接收的所有的路由集合;
BGP顺序调用下列消除规则:
路由被指定一个本地偏好值作为路由的属性;
- 本地偏好,会被同一AS中其他路由器学习到;
- 具有最高本地偏好的路由将被选择
在所有具有
相同本地偏好值
的路由中,具有最短AS-PATH的路由将被选择;
- BGP使用距离向量算法,距离测度使用AS跳数目;
在所有具有
相同本地偏好值和相同AS-PATH长度
,选择最靠近NEXT-HOP路由器的路由;
- 最靠近,指到达NEXT-HOP接口最低费用路由路径,使用AS内部算法来决定,热土豆路由选择;
仍然留下多条路由,该路由器使用BGP标识符来选择路由;
时间原则:PAGE275
4. 路由选择策略
桩网络(stub network): 不会进行流量转发,所有离开AS进入桩网络的流量,必然是去往桩网络,所有离开桩网络的流量,必然是进入其他AS;
- 通过控制BGP路由的方式可以实现,两个连入桩网络的网络流量不会被该桩网络转发,原因就是这两个连入的网络不会将转发链路通告给桩网路;
- ISP之间的路由选择:任何穿越莫ISP主干网的流量必须是其源地址或者目的,位于该ISP的某个客户网络中;不然这些流量将会免费搭车通过该ISP的网络;
- AS和AS之间的路由选择目标之间的差别:
- 策略
- 规模
- 性能
- PAGE277
4.7 广播和多播路由选择
- 广播路由选择 broadcast routing
- 网络层提供了从一个源结点到网络中其他所有结点交付分组的服务
- 多播路由选择 multicast routing
- 使单个源结点能向其他网络结点的一个子集发送分组的副本
4.7.1 广播路由选择算法
- N次单播
- 源结点产生分组的N份副本,对不同目的地的每个副本进行编址,并用单播路由器选择向N个目的地传输N份副本;
- 无需网络层路由选择协议以及分组复制或转发功能;
- 缺陷
- 生成了太多冗余副本,让接收结点再去生成冗余副本更加有效
- 需要另外的协议,如广播成员或目的地注册协议,会怎加更多开销,且协议变得复杂;
- 单播路由情况下,选择基础设施来取得广播并不明智;
1. 无控制洪泛
- 洪泛 flooding
- 源结点向所有的邻居结点发送分组副本,当某个结点接收到一个广播分组时,复制该分组并向所有的邻居转发;(不会再次给发送方邻居转发)
- 缺陷
- 此连通图具有圈,一个或者多个广播分组将会无休止的循环下去,例如R2,R3,R4互相连通为圈,则R2向3和4广播,3和4复制后又像4和3广播,4和3复制后又像2广播;
- 广播风暴 broadcast storm,导致无休止的广播分组的复制;
2. 受控洪泛 controlled flooding
- 序号控制洪泛 sequence-number-controlled flooding
- 源结点,将其地址和广播序号 broadcast sequence number放入广播分组;再向邻居发送副本;
- 每个结点维护一个收到分组标示的列表
- 收到广播分组后,首先检查是否存在列表中,如果再,直接丢弃,如果不再,则更新列表,并复制发送给邻居结点;
- 反向路经转发 reverse path forwarding,RPF 反向路经广播
- 当一台路由器接收到一个“源”的广播分组时,只有分组到达的路经 = 路由器到“源”的最短单播路经时,路由器才会接收该广播分组并向其他邻居转发;
3. 生成树广播
序号控制洪泛和RPF避免了广播风暴,但是无法完全避免冗余分组的传输;
- 生成树 spanning tree
- 所有生成树中费用最小的生成树:最小生成树
- 广播方法
- 最网络结点构造一颗生成树
- 源结点向所有属于生成树的特定链路发送分组
- 接收广播分组的结点则向生成树中所有邻居转发该分组(接收该分组的邻居除外)
- 生成树生成算法
- 基于中心的方法 center-based approach
- 定义一个中心点为汇合点 rendezvous point 或者 核 core
- 结点向中心结点单播加入树 tree-join 报文,加入树报文使用单播路由选择朝中心结点转发,直到到达一个已经属于生成树的结点或者中心结点;
- 加入树报文经过的路经定义了发起加入树报文的边缘结点和中心结点之间的分支,新的分支已经被认为能够嫁接到现有的生成树上了;
- 生成过程:PAGE281
- 基于中心的方法 center-based approach
4. 实践中的广播算法
- 实践中,广播协议被应用于:网络层和应用层
- 在Gnutella网络中,使用应用级的广播;
- 在OSPF路由选择算法和 中间系统到中间系统 IS-IS路由选择算法中,使用一种序号来靠内阁制洪泛;
- OSPF使用一个32bit的序号和一个16bit的age字段来标识LSA 广播链路状态通知;
- 详情: PAGE 281 282
4.7.2 多播
多播(multicast)服务
,多播服务将分组交付给网络中一个结点的子集;
- 应用程序要求将分组从一个或多个发送方交付给一组接收方;
- 批量数据传输
- 流媒体服务
- 数据共享应用
- Web缓存更新
- 交互式游戏
- 应用程序要求将分组从一个或多个发送方交付给一组接收方;
多播数据报,使用间接地址 address indirection来编址,用一个标识来表示一组接收方,寻址到该组的分组副本被交付给所有与该分组相关联的多播接收方,且使用单一标识符;
D类多播地址
与D类多播地址,相关联的接收方小组为多播组 multicast group
每台主机由一个唯一的单播IP地址,且完全独立于主机所参与的多播地址
IGMP (因特网组管理协议,与ICMP因特网连接管理协议完全不同)
1. 因特网组管理协议 IGMP
- IGMP为主机提供手段,通知与其相连的路由器
- 主机上的应用程序想要加入一个特定的多播组,IGMP与多播路由选择协议 互补组成;
IGMP
- IGMP三种报文类型
- membership_query
- 确定主机已经加入所有的多播集合
- membership_report
- 响应membership_query报文
- 主机首次加入多播组,主机产生membership_report报文,无需等到路由器的membership_query报文
- leave_group
- 可选
- 路由器检测主机离开多播组,使用membership_query,当无主机响应具体组地址membership_query报文时,路由器推断出没有任何主机在当前多播组了
- 软状态
- IGMP中,多播组未被 “来自主机的membership_report” 报文显示的更新,通过超时事件将主机从多播组中删除;
- 软状态来源:PAGE284
- membership_query
- IGMP报文和ICMP报文类似,封装在一个IP数据报中,使用IP上层协议号为2;
2. 多播路由选择算法
选择方法
- 多播路由器选择的目标就是发现一颗链路树,这些链路连接了所有属于该多播组的相连主机的路由器;
- 多播分组 将 沿着这颗树从发送方路由到所有属于该多播树的主机;
确定多播路由选择树的方法:
使用一棵组共享树的多播路由选择;
- 使用基于中心的方法来构建多播路由选择树;
- 属于多播组的主机,与主机相连的边缘路由将用“单播的方式”向中的结点发送加入报文;
- 关键:中心选择算法
使用一颗基于源的树的多播路由选择;
为多播组中的源构建一个多播路由选择树;
使用RPF算法,来构造一个多播转发树;
缺陷与接近方法:
数千台下游路由器都将收到一个不想要的多播分组;
剪枝
一台接收到多播分组的多播路由器,如果它没有要加入多播组的相连主机,则向上游返回一个剪枝报文;
对一个路由器来说,如果它收到了来自下游每台路由器的剪枝报文,那么它会向自己上游的路由器发送剪枝报告;
反向路经广播算法 RPF
3. 因特网中的多播路由选择
距离向量多播路由选择协议 Distance Vector Multicast Routing Protocol, DVMRP
- 实现了反向路经转发
- 实现了剪枝算法的基于源的树
- 使用RFP算法
协议无关的多播路由选择协议 Protocol Independent Multicast, PIM
- 稠密模式 Dense mode
- 稀疏模式 sparse mode
不同域间的多播,使用域间BGP;
详情:PAGE 286
5.链路层和局域网
5.1概述

节点:运行链路层协议的任何设备
链路:物理通道
数据链路:逻辑通道
帧:链路层分组,封装网络层数据报
作用:在物理层服务基础上向网络层提供服务,将物理层提供的可能出错的链接改造成一条无差错的链接
功能:成帧、链路接入、可靠交付、差错检测和纠错
5.2封装成帧及透明传输
5.3差错控制及纠正技术
差错:位错、帧错
差错控制:检错编码和纠错编码
检错编码:奇偶校验码和循环冗余码CRC
奇偶校验码
CRC:异或计算(同0异1)
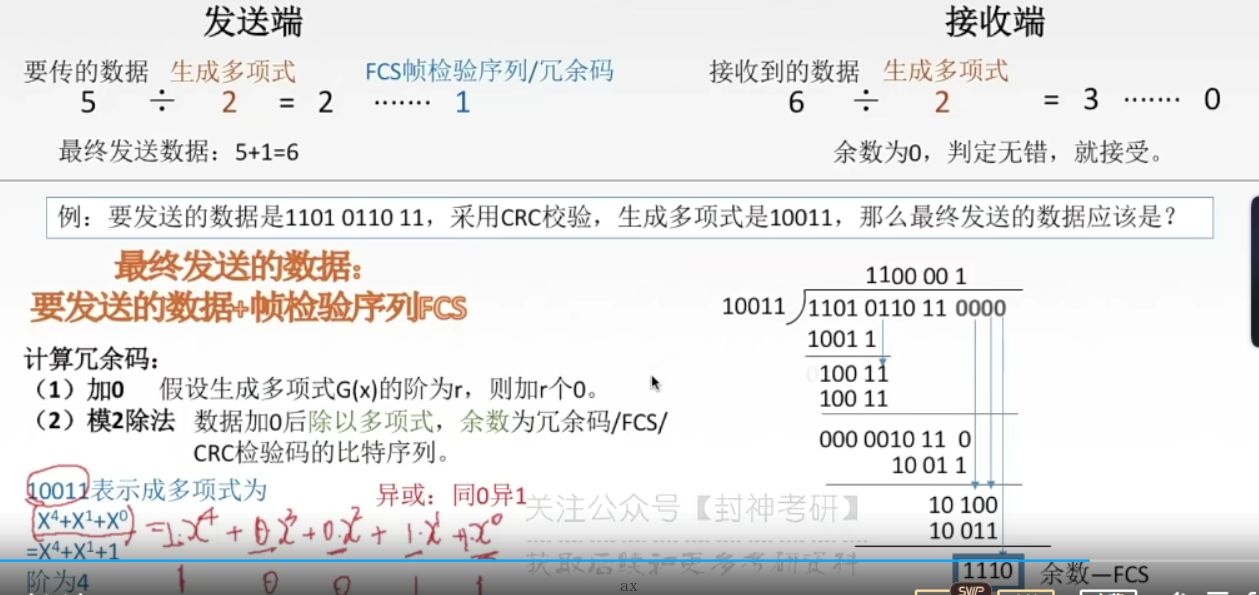
纠错编码:海明码
5.4流量控制与可靠传输机制
5.5多路访问链路和协议
5.5.1信道划分协议
TDM时分多路复用
FDM频分多路复用
CDMA码分多址:类似于时隙和频隙的一种划分方式,仅作了解
5.5.2随机接入协议
时隙ALOHA:ALOHA的改进版,把时间分为相同大小的时间片SLOT,不监听信道、按时间槽发送、随机重发(时间片开始)、想发就发,碰撞概率仍然很大
ALOHA:不监听信道、不按时间槽发送、随机重发、想发就发,碰撞概率很大
CSMA载波监听:先听再发,几种方式如下:
- 1坚持:空闲时可能有多个计算机同时发送,可能导致冲突
- 非坚持:如果监听到忙,就放弃监听,等待随机时间后再监听
- p坚持:和1坚持的区别就是发送数据的概率,产生冲突的概率小一点
CSMA/CD:碰撞检测,先听再发,边听边发,冲突停发,随机重发。最小帧长的规定。
- 如何重发:截断二进制指数退避算法 P300:第一次在{0,1}中等概率选择一个,第二次在{0,1,2,3}中等概率选择一个… …第十次在{0,1,……,1023}中等概率选择一个。
5.5.3轮流协议
5.4.1链路层寻址和ARP
发送数据报到子网以内
- 局域网,不使用IP地址寻址,通过链路层地址MAC寻址
- 如果ARP表中有对应的项,那么正常发送即可。
- 如果ARP表中没有对应IP的MAC地址,那么发送方向他的适配器传输一个ARP查询分组,指示适配器用MAC广播地址将这个分组发送出去,然后局域网中其他设备检查自己的ARP表,将与之匹配的ARP项返回给查询主机,查询主机再进行后续的操作。
发送数据报到子网以外
- 子网1向子网2发送数据报,子网1中的设备向子网1中的设备查询,子网1中的路由器发现该地址是向它寻址的,因此把这个帧传给路由器的网络层。路由器通过查询转发表将该帧转发到子网2的路由器接口,然后该接口把包传递给他的适配器,再通过查询ARP来查询到MAC地址封装到一个新的帧,最后将帧转发到目的地。
5.4.2以太网
以太网是目前最流行的有线局域网技术
以太网帧结构
- 前同步码|目的地址|源地址|类型|数据| |CRC
- 数据:这个字段承载了IP数据报
- 目的地址:包含目的适配器的MAC地址
- 源地址:包含了源MAC地址
- 前同步码|目的地址|源地址|类型|数据| |CRC
以太网技术
以太网向网络层提供不可靠服务:帧没有通过CRC校验时只是舍弃该帧
以太网向网络层提供无连接服务:不事先握手
5.4.3链路层交换机
交换机转发和过滤
- 过滤:决定一个帧是否转发和是否丢弃
- 转发:决定一个帧被导向哪个接口
- 交换机的转发和过滤借助于交换机表
自学习
交换机表是自动、动态、自治的建立的,即插即用设备
交换机表初始为空
对于每个接口接收到的入帧,交换机将其存储
老化器:一段时间,该地址不活跃,交换机就将其删除
链路层交换机的性质 p315
- 消除碰撞
- 异质的链路:交换机将链路隔离,因此局域网中不同的链路能一不一样的速度、介质存在。
- 管理:交换机可以为网络管理提供便捷
交换机和路由器的比较
交换机基于MAC地址转发(第二层)、路由器基于IP地址转发(第三层),现代交换机两种都有。
优点 缺点 交换机 1、即插即用。2、相对高的分组过滤和转发速率。 为了防止广播帧的循环,交换网络的活跃拓扑严格限制成一棵树,但是交换机对这个没有限制,有可能导致以太网的崩溃。 路由器 1、一般分组不会被循环。允许了非常丰富的拓扑结构来构建因特网。2、对第二层的广播风暴构建了防火墙。 处理时间比交换机更长
5.4.4虚拟局域网VLAN
在一个单一的物理局域网中定义多个虚拟局域网,支持VLAN的交换机的端口被管理员划分为组

这些端口中的广播流量仅能到达该组中的其他端口
- 怎么解决完全隔离带来的组与组之间传递的问题呢:VLAN干线连接
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!